Netty 源码分析 —— NIO 基础(一)
1. 概述
Java NIO( New IO 或者 Non Blocking IO ) ,从 Java 1.4 版本开始引入的非阻塞 IO ,用于替换标准( 有些文章也称为传统,或者 Blocking IO 。下文统称为 BIO ) Java IO API 的 IO API 。
老艿艿:在一些文章中,会将 Java NIO 描述成异步 IO ,实际是不太正确的: Java NIO 是同步 IO ,Java AIO ( 也称为 NIO 2 )是异步 IO。具体原因,推荐阅读文章:
总结来说,在 Unix IO 模型的语境下:
同步和异步的区别:数据拷贝阶段是否需要完全由操作系统处理。
阻塞和非阻塞操作:是针对发起 IO 请求操作后,是否有立刻返回一个标志信息而不让请求线程等待。
因此,Java NIO 是同步且非阻塞的 IO 。
2. 核心组件
Java NIO 由如下三个核心组件组成:
Channel
Buffer
Selector
后续的每篇文章,我们会分享对应的一个组件。
3. NIO 和 BIO 的对比
NIO 和 BIO 的区别主要体现在三个方面:
其中,选择器( Selector )是 NIO 能实现非阻塞的基础。
3.1 基于 Buffer 与基于 Stream
BIO 是面向字节流或者字符流的,而在 NIO 中,它摒弃了传统的 IO 流,而是引入 Channel 和 Buffer 的概念:从 Channel 中读取数据到 Buffer 中,或者将数据从 Buffer 中写到 Channel 中。
① 那么什么是基于 Stream呢?
在一般的 Java IO 操作中,我们以流式的方式,顺序的从一个 Stream 中读取一个或者多个字节,直至读取所有字节。因为它没有缓存区,所以我们就不能随意改变读取指针的位置。
② 那么什么是基于 Buffer 呢?
基于 Buffer 就显得有点不同了。我们在从 Channel 中读取数据到 Buffer 中,这样 Buffer 中就有了数据后,我们就可以对这些数据进行操作了。并且不同于一般的 Java IO 操作那样是顺序操作,NIO 中我们可以随意的读取任意位置的数据,这样大大增加了处理过程中的灵活性。
写入操作,也符合上述读取操作的情况
3.2 阻塞与非阻塞 IO
Java IO 的各种流是阻塞的 IO 操作。这就意味着,当一个线程执行读或写 IO 操作时,该线程会被阻塞,直到有一些数据被读取,或者数据完全写入。
Java NIO 可以让我们非阻塞的使用 IO 操作。例如:
当一个线程执行从 Channel 执行读取 IO 操作时,当此时有数据,则读取数据并返回;当此时无数据,则直接返回而不会阻塞当前线程。
当一个线程执行向 Channel 执行写入 IO 操作时,不需要阻塞等待它完全写入,这个线程同时可以做别的事情。
也就是说,线程可以将非阻塞 IO 的空闲时间用于在其他 Channel 上执行 IO 操作。所以,一个单独的线程,可以管理多个 Channel 的读取和写入 IO 操作。
3.3 Selector
Java NIO 引入 Selector ( 选择器 )的概念,它是 Java NIO 得以实现非阻塞 IO 操作的最最最关键。
我们可以注册多个 Channel 到一个 Selector 中。而 Selector 内部的机制,就可以自动的为我们不断的执行查询( select )操作,判断这些注册的 Channel 是否有已就绪的 IO 事件( 例如可读,可写,网络连接已完成 )。
通过这样的机制,一个线程通过使用一个 Selector ,就可以非常简单且高效的来管理多个 Channel 了。
4. NIO 和 AIO 的对比
考虑到 Netty 4.1.X 版本实际并未基于 Java AIO 实现,所以我们就省略掉这块内容。那么,感兴趣的同学,可以自己 Google 下 Java NIO 和 Java AIO 的对比。
具体为什么 Netty 4.1.X 版本不支持 Java AIO 的原因,可参见 《Netty(二):Netty 为啥去掉支持 AIO ?》 文章。
也因此,Netty 4.1.X 一般情况下,使用的是同步非阻塞的 NIO 模型。当然,如果真的有必要,也可以使用同步阻塞的 BIO 模型。
参考文章如下:
Netty 源码分析 —— NIO 基础(二)之 Channel
1. 概述
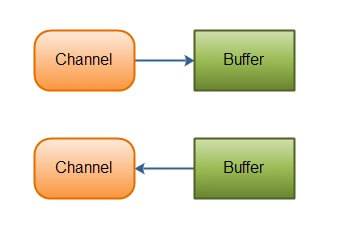
在 Java NIO 中,基本上所有的 IO 操作都是从 Channel 开始。数据可以从 Channel 读取到 Buffer 中,也可以从 Buffer 写到 Channel 中。如下图所示:
2. NIO Channel 对比 Java Stream
NIO Channel 类似 Java Stream ,但又有几点不同:
对于同一个 Channel ,我们可以从它读取数据,也可以向它写入数据。而对于同一个 Stream ,通畅要么只能读,要么只能写,二选一( 有些文章也描述成“单向”,也是这个意思 )。
Channel 可以非阻塞的读写 IO 操作,而 Stream 只能阻塞的读写 IO 操作。
Channel 必须配合 Buffer 使用,总是先读取到一个 Buffer 中,又或者是向一个 Buffer 写入。也就是说,我们无法绕过 Buffer ,直接向 Channel 写入数据。
3. Channel 的实现
Channel 在 Java 中,作为一个接口,java.nio.channels.Channel ,定义了 IO 操作的连接与关闭。代码如下:
public interface Channel extends Closeable {
/**
* 判断此通道是否处于打开状态。
*/
public boolean isOpen();
/**
*关闭此通道。
*/
public void close() throws IOException;
}Channel 有非常多的实现类,最为重要的四个 Channel 实现类如下:
SocketChannel :一个客户端用来发起 TCP 的 Channel 。
ServerSocketChannel :一个服务端用来监听新进来的连接的 TCP 的 Channel 。对于每一个新进来的连接,都会创建一个对应的 SocketChannel 。
DatagramChannel :通过 UDP 读写数据。
FileChannel :从文件中,读写数据。
3.1 ServerSocketChannel
《Java NIO系列教程(九) ServerSocketChannel》
3.2 SocketChannel
《Java NIO 系列教程(八) SocketChannel》
3.3 DatagramChannel
《Java NIO系列教程(十) Java NIO DatagramChannel》
3.4 FileChannel
参考文章如下:
Netty 源码分析 —— NIO 基础(三)之 Buffer
1. 概述
一个 Buffer ,本质上是内存中的一块,我们可以将数据写入这块内存,之后从这块内存获取数据。通过将这块内存封装成 NIO Buffer 对象,并提供了一组常用的方法,方便我们对该块内存的读写。
Buffer 在 java.nio 包中实现,被定义成抽象类,从而实现一组常用的方法。整体类图如下:
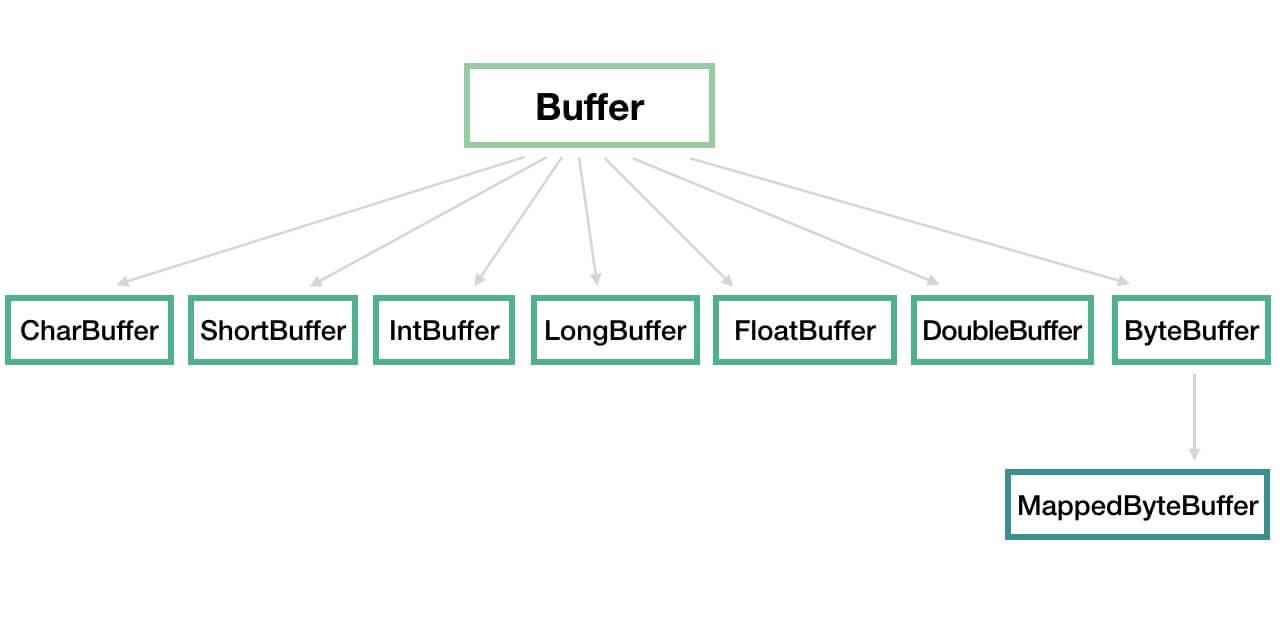
我们可以将 Buffer 理解为一个数组的封装,例如 IntBuffer、CharBuffer、ByteBuffer 等分别对应
int[]、char[]、byte[]等。MappedByteBuffer 用于实现内存映射文件,不是本文关注的重点。因此,感兴趣的,可以自己 Google 了解,还是蛮有趣的。
2. 基本属性
Buffer 中有 4 个非常重要的属性:capacity、limit、position、mark 。代码如下:
public abstract class Buffer {
// Invariants: mark <= position <= limit <= capacity
private int mark = -1;
private int position = 0;
private int limit;
private int capacity;
// Used only by direct buffers
// NOTE: hoisted here for speed in JNI GetDirectBufferAddress
long address;
Buffer(int mark, int pos, int lim, int cap) { // package-private
if (cap < 0)
throw new IllegalArgumentException("Negative capacity: " + cap);
this.capacity = cap;
limit(lim);
position(pos);
if (mark >= 0) {
if (mark > pos)
throw new IllegalArgumentException("mark > position: ("
+ mark + " > " + pos + ")");
this.mark = mark;
}
}
// ... 省略具体方法的代码
}capacity属性,容量,Buffer 能容纳的数据元素的最大值。这一容量在 Buffer 创建时被赋值,并且永远不能被修改。Buffer 分成写模式和读模式两种情况。如下图所示:
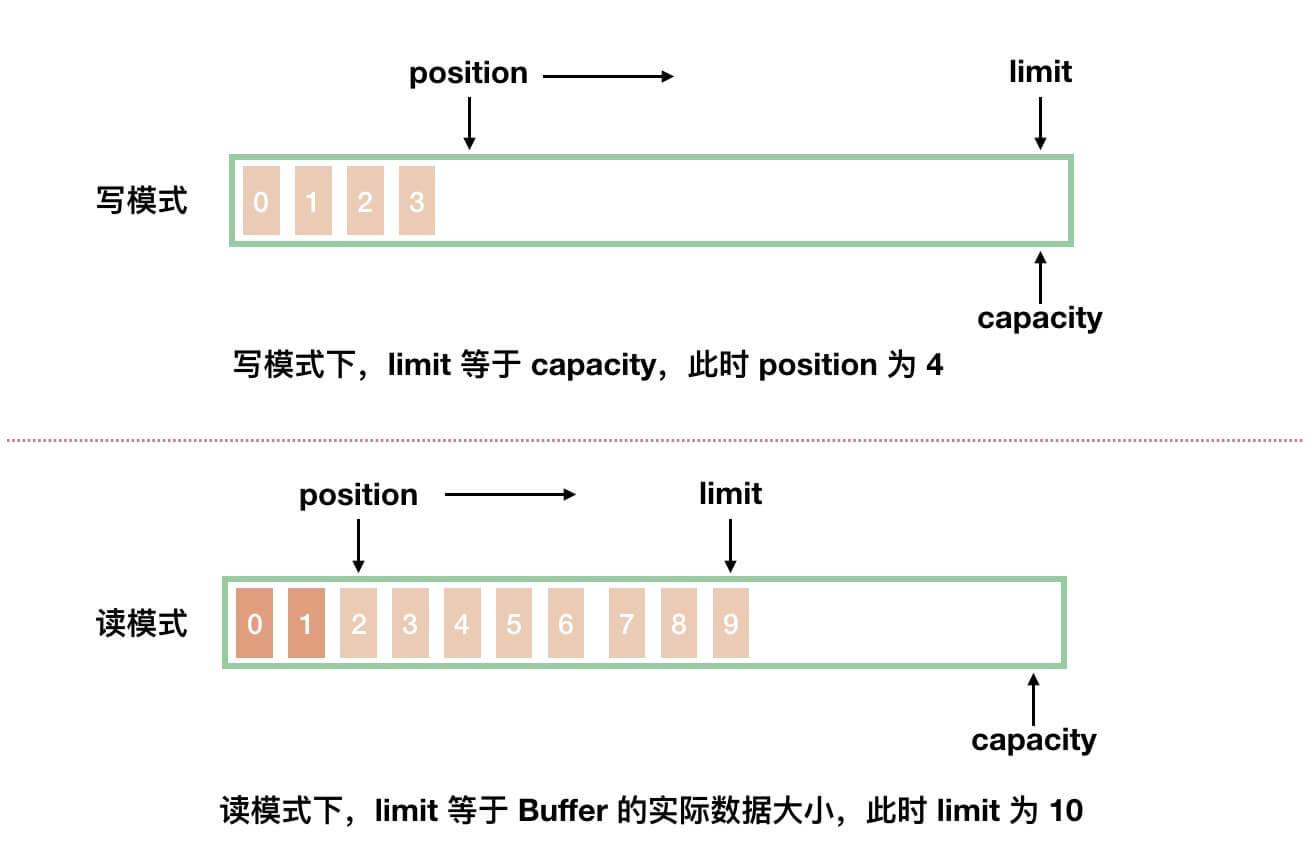
从图中,我们可以看到,两种模式下,
position和limit属性分别代表不同的含义。下面,我们来分别看看。
position属性,位置,初始值为 0 。写模式下,每往 Buffer 中写入一个值,
position就自动加 1 ,代表下一次的写入位置。读模式下,每从 Buffer 中读取一个值,
position就自动加 1 ,代表下一次的读取位置。( 和写模式类似 )
limit属性,上限。写模式下,代表最大能写入的数据上限位置,这个时候
limit等于capacity。读模式下,在 Buffer 完成所有数据写入后,通过调用
#flip()方法,切换到读模式。此时,limit等于 Buffer 中实际的数据大小。因为 Buffer 不一定被写满,所以不能使用capacity作为实际的数据大小。
mark属性,标记,通过#mark()方法,记录当前position;通过reset()方法,恢复position为标记。写模式下,标记上一次写位置。
读模式下,标记上一次读位置。
从代码注释上,我们可以看到,四个属性总是遵循如下大小关系:
mark <= position <= limit <= capacity写到此处,忍不住吐槽了下,Buffer 的读模式和写模式,我认为是有一点“糟糕”。相信大多数人在理解的时候,都会开始一脸懵逼的状态。相比较来说,Netty 的 ByteBuf 就优雅的非常多,基本属性设计如下:
0 <= readerIndex <= writerIndex <= capacity通过
readerIndex和writerIndex两个属性,避免出现读模式和写模式的切换。
3. 创建 Buffer
① 每个 Buffer 实现类,都提供了 #allocate(int capacity) 静态方法,帮助我们快速实例化一个 Buffer 对象。以 ByteBuffer 举例子,代码如下:
// ByteBuffer.java
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}ByteBuffer 实际是个抽象类,返回的是它的基于堆内( Non-Direct )内存的实现类 HeapByteBuffer 的对象。
② 每个 Buffer 实现类,都提供了 #wrap(array) 静态方法,帮助我们将其对应的数组包装成一个 Buffer 对象。还是以 ByteBuffer 举例子,代码如下:
// ByteBuffer.java
public static ByteBuffer wrap(byte[] array, int offset, int length){
try {
return new HeapByteBuffer(array, offset, length);
} catch (IllegalArgumentException x) {
throw new IndexOutOfBoundsException();
}
}
public static ByteBuffer wrap(byte[] array) {
return wrap(array, 0, array.length);
}和
#allocate(int capacity)静态方法一样,返回的也是 HeapByteBuffer 的对象。
③ 每个 Buffer 实现类,都提供了 #allocateDirect(int capacity) 静态方法,帮助我们快速实例化一个 Buffer 对象。以 ByteBuffer 举例子,代码如下:
// ByteBuffer.java
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}和
#allocate(int capacity)静态方法不一样,返回的是它的基于堆外( Direct )内存的实现类 DirectByteBuffer 的对象。
3.1 关于 Direct Buffer 和 Non-Direct Buffer 的区别
FROM 《Java NIO 的前生今世 之三 NIO Buffer 详解》
Direct Buffer:
所分配的内存不在 JVM 堆上, 不受 GC 的管理.(但是 Direct Buffer 的 Java 对象是由 GC 管理的, 因此当发生 GC, 对象被回收时, Direct Buffer 也会被释放)
因为 Direct Buffer 不在 JVM 堆上分配, 因此 Direct Buffer 对应用程序的内存占用的影响就不那么明显(实际上还是占用了这么多内存, 但是 JVM 不好统计到非 JVM 管理的内存.)
申请和释放 Direct Buffer 的开销比较大. 因此正确的使用 Direct Buffer 的方式是在初始化时申请一个 Buffer, 然后不断复用此 buffer, 在程序结束后才释放此 buffer.
使用 Direct Buffer 时, 当进行一些底层的系统 IO 操作时, 效率会比较高, 因为此时 JVM 不需要拷贝 buffer 中的内存到中间临时缓冲区中.
Non-Direct Buffer:
直接在 JVM 堆上进行内存的分配, 本质上是 byte[] 数组的封装.
因为 Non-Direct Buffer 在 JVM 堆中, 因此当进行操作系统底层 IO 操作中时, 会将此 buffer 的内存复制到中间临时缓冲区中. 因此 Non-Direct Buffer 的效率就较低.
4. 向 Buffer 写入数据
每个 Buffer 实现类,都提供了 #put(...) 方法,向 Buffer 写入数据。以 ByteBuffer 举例子,代码如下:
// 写入 byte
public abstract ByteBuffer put(byte b);
public abstract ByteBuffer put(int index, byte b);
// 写入 byte 数组
public final ByteBuffer put(byte[] src) { ... }
public ByteBuffer put(byte[] src, int offset, int length) {...}
// ... 省略,还有其他 put 方法对于 Buffer 来说,有一个非常重要的操作就是,我们要讲来自 Channel 的数据写入到 Buffer 中。在系统层面上,这个操作我们称为读操作,因为数据是从外部( 文件或者网络等 )读取到内存中。示例如下:
int num = channel.read(buffer);上述方法会返回从 Channel 中写入到 Buffer 的数据大小。对应方法的代码如下:
public interface ReadableByteChannel extends Channel {
public int read(ByteBuffer dst) throws IOException;
}注意,通常在说 NIO 的读操作的时候,我们说的是从 Channel 中读数据到 Buffer 中,对应的是对 Buffer 的写入操作,初学者需要理清楚这个。
5. 从 Buffer 读取数据
每个 Buffer 实现类,都提供了 #get(...) 方法,从 Buffer 读取数据。以 ByteBuffer 举例子,代码如下:
// 读取 byte
public abstract byte get();
public abstract byte get(int index);
// 读取 byte 数组
public ByteBuffer get(byte[] dst, int offset, int length) {...}
public ByteBuffer get(byte[] dst) {...}
// ... 省略,还有其他 get 方法对于 Buffer 来说,还有一个非常重要的操作就是,我们要讲来向 Channel 的写入 Buffer 中的数据。在系统层面上,这个操作我们称为写操作,因为数据是从内存中写入到外部( 文件或者网络等 )。示例如下:
int num = channel.write(buffer);上述方法会返回向 Channel 中写入 Buffer 的数据大小。对应方法的代码如下:
public interface WritableByteChannel extends Channel {
public int write(ByteBuffer src) throws IOException;
}6. rewind() v.s. flip() v.s. clear()
6.1 flip
如果要读取 Buffer 中的数据,需要切换模式,从写模式切换到读模式。对应的为 #flip() 方法,代码如下
public final Buffer flip() {
limit = position; // 设置读取上限
position = 0; // 重置 position
mark = -1; // 清空 mark
return this;
}使用示例,代码如下:
buf.put(magic); // Prepend header
in.read(buf); // Read data into rest of buffer
buf.flip(); // Flip buffer
channel.write(buf); // Write header + data to channel6.2 rewind
#rewind() 方法,可以重置 position 的值为 0 。因此,我们可以重新读取和写入 Buffer 了。
大多数情况下,该方法主要针对于读模式,所以可以翻译为“倒带”。也就是说,和我们当年的磁带倒回去是一个意思。代码如下:
public final Buffer rewind() {
position = 0; // 重置 position
mark = -1; // 清空 mark
return this;
}从代码上,和
#flip()相比,非常类似,除了少了第一行的limit = position的代码块。
使用示例,代码如下:
channel.write(buf); // Write remaining data
buf.rewind(); // Rewind buffer
buf.get(array); // Copy data into array6.3 clear
#clear() 方法,可以“重置” Buffer 的数据。因此,我们可以重新读取和写入 Buffer 了。
大多数情况下,该方法主要针对于写模式。代码如下:
public final Buffer clear() {
position = 0; // 重置 position
limit = capacity; // 恢复 limit 为 capacity
mark = -1; // 清空 mark
return this;
}从源码上,我们可以看出,Buffer 的数据实际并未清理掉,所以使用时需要注意。
读模式下,尽量不要调用
#clear()方法,因为limit可能会被错误的赋值为capacity。相比来说,调用#rewind()更合理,如果有重读的需求。
使用示例,代码如下:
buf.clear(); // Prepare buffer for reading
in.read(buf); // Read data7. mark() 搭配 reset()
7.1 mark
#mark() 方法,保存当前的 position 到 mark 中。代码如下:
public final Buffer mark() {
mark = position;
return this;
}7.2 reset
#reset() 方法,恢复当前的 postion 为 mark 。代码如下:
public final Buffer reset() {
int m = mark;
if (m < 0)
throw new InvalidMarkException();
position = m;
return this;
}8. 其它方法
Buffer 中还有其它方法,比较简单,所以大家自己研究噢。代码如下:
// ========== capacity ==========
public final int capacity() {
return capacity;
}
// ========== position ==========
public final int position() {
return position;
}
public final Buffer position(int newPosition) {
if ((newPosition > limit) || (newPosition < 0))
throw new IllegalArgumentException();
position = newPosition;
if (mark > position) mark = -1;
return this;
}
// ========== limit ==========
public final int limit() {
return limit;
}
public final Buffer limit(int newLimit) {
if ((newLimit > capacity) || (newLimit < 0))
throw new IllegalArgumentException();
limit = newLimit;
if (position > limit) position = limit;
if (mark > limit) mark = -1;
return this;
}
// ========== mark ==========
final int markValue() { // package-private
return mark;
}
final void discardMark() { // package-private
mark = -1;
}
// ========== 数组相关 ==========
public final int remaining() {
return limit - position;
}
public final boolean hasRemaining() {
return position < limit;
}
public abstract boolean hasArray();
public abstract Object array();
public abstract int arrayOffset();
public abstract boolean isDirect();
// ========== 下一个读 / 写 position ==========
final int nextGetIndex() { // package-private
if (position >= limit)
throw new BufferUnderflowException();
return position++;
}
final int nextGetIndex(int nb) { // package-private
if (limit - position < nb)
throw new BufferUnderflowException();
int p = position;
position += nb;
return p;
}
final int nextPutIndex() { // package-private
if (position >= limit)
throw new BufferOverflowException();
return position++;
}
final int nextPutIndex(int nb) { // package-private
if (limit - position < nb)
throw new BufferOverflowException();
int p = position;
position += nb;
return p;
}
final int checkIndex(int i) { // package-private
if ((i < 0) || (i >= limit))
throw new IndexOutOfBoundsException();
return i;
}
final int checkIndex(int i, int nb) { // package-private
if ((i < 0) || (nb > limit - i))
throw new IndexOutOfBoundsException();
return i;
}
// ========== 其它方法 ==========
final void truncate() { // package-private
mark = -1;
position = 0;
limit = 0;
capacity = 0;
}
static void checkBounds(int off, int len, int size) { // package-private
if ((off | len | (off + len) | (size - (off + len))) < 0)
throw new IndexOutOfBoundsException();
}参考文章如下:
Netty 源码分析 —— NIO 基础(四)之 Selector
这篇文章解释了 Java NIO 中 Selector 的概念、作用、使用方法以及一些注意事项,并用简单的代码示例说明了如何使用 Selector 来管理多个 Channel。
Key Takeaways
Selector 是 Java NIO 的核心组件,用于轮询多个 Channel 的状态是否处于可读或可写。
Selector 通过将 Channel 注册到其中,并不断轮询注册在其上的 Channel 来管理多个 Channel。
使用 Selector 可以用更少的线程来处理多个 Channel,但每个 Channel 的处理效率可能会降低。
Channel 要注册到 Selector 中,必须是非阻塞的。
Selector 可以监听四种事件:连接完成、接受新连接、读、写。
SelectionKey 类表示一个 Channel 和一个 Selector 的注册关系,包含感兴趣的事件集合、就绪的事件集合、Channel、Selector 和附加对象。
Selector 提供三种选择方法:select()、select(long timeout) 和 selectNow(),分别对应阻塞、超时和立即返回。
1. 概述
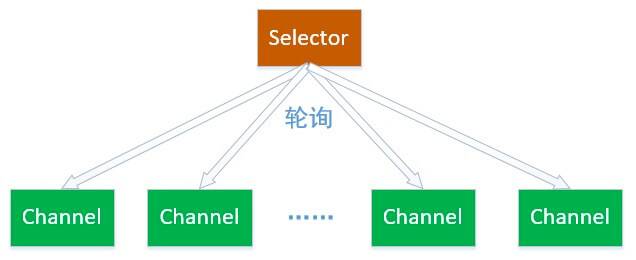
Selector , 一般称为选择器。它是 Java NIO 核心组件中的一个,用于轮询一个或多个 NIO Channel 的状态是否处于可读、可写。如此,一个线程就可以管理多个 Channel ,也就说可以管理多个网络连接。也因此,Selector 也被称为多路复用器。
那么 Selector 是如何轮询的呢?
首先,需要将 Channel 注册到 Selector 中,这样 Selector 才知道哪些 Channel 是它需要管理的。
之后,Selector 会不断地轮询注册在其上的 Channel 。如果某个 Channel 上面发生了读或者写事件,这个 Channel 就处于就绪状态,会被 Selector 轮询出来,然后通过 SelectionKey 可以获取就绪 Channel 的集合,进行后续的 I/O 操作。
下图是一个 Selector 管理三个 Channel 的示例:
2. 优缺点
① 优点
使用一个线程能够处理多个 Channel 的优点是,只需要更少的线程来处理 Channel 。事实上,可以使用一个线程处理所有的 Channel 。对于操作系统来说,线程之间上下文切换的开销很大,而且每个线程都要占用系统的一些资源( 例如 CPU、内存 )。因此,使用的线程越少越好。
② 缺点
因为在一个线程中使用了多个 Channel ,因此会造成每个 Channel 处理效率的降低。
当然,Netty 在设计实现上,通过 n 个线程处理多个 Channel ,从而很好的解决了这样的缺点。其中,n 的指的是有限的线程数,默认情况下为 CPU * 2 。
3. Selector 类图
Selector 在 java.nio 包中,被定义成抽象类,整体实现类图如下:
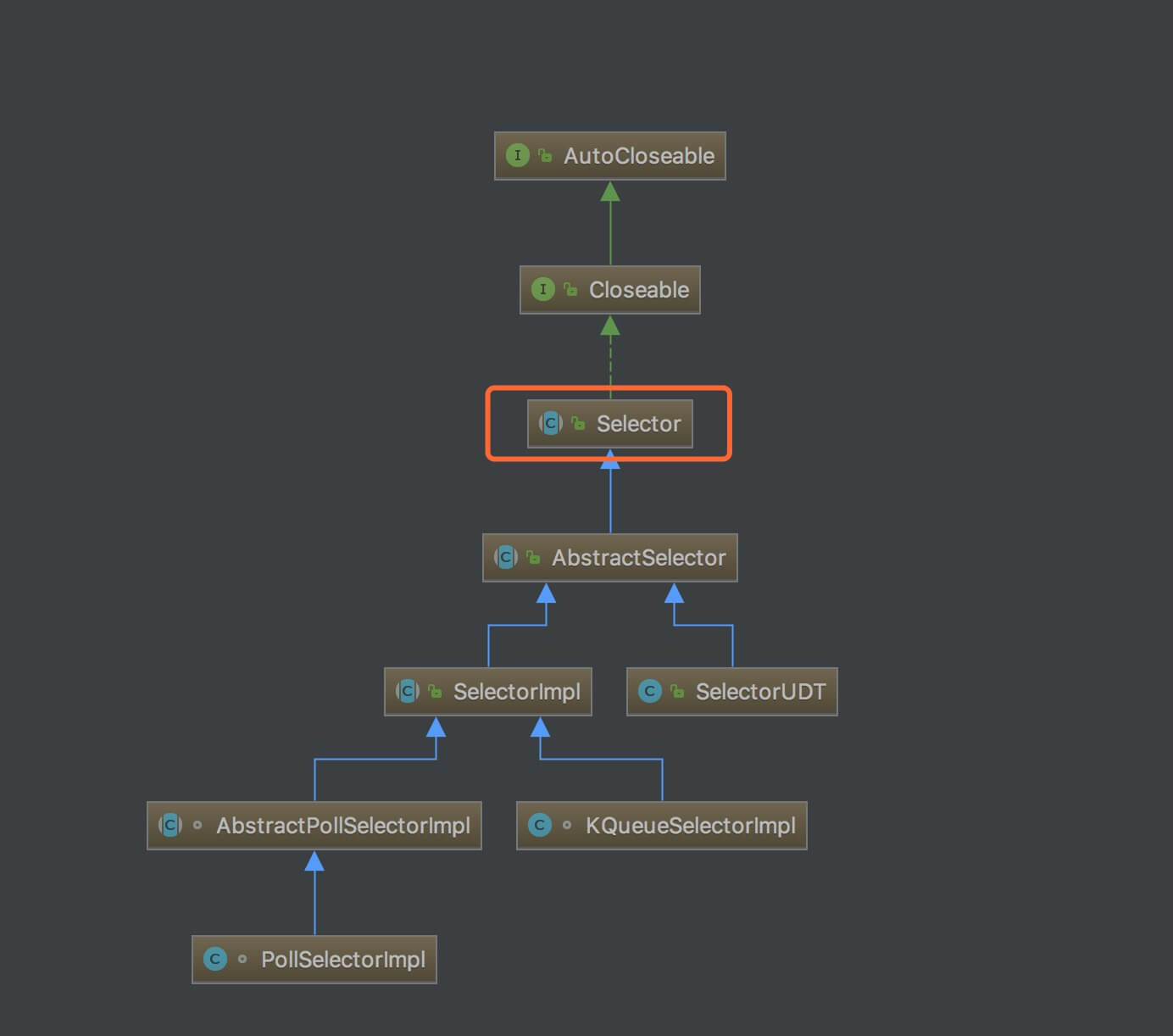
Selector 的实现不是本文的重点,感兴趣的可以看看占小狼的 《深入浅出NIO之Selector实现原理》 。
3. 创建 Selector
通过 #open() 方法,我们可以创建一个 Selector 对象。代码如下:
Selector selector = Selector.open();4. 注册 Chanel 到 Selector 中
为了让 Selector 能够管理 Channel ,我们需要将 Channel 注册到 Selector 中。代码如下:
channel.configureBlocking(false); // <1>
SelectionKey key = channel.register(selector, SelectionKey.OP_READ);注意,如果一个 Channel 要注册到 Selector 中,那么该 Channel 必须是非阻塞,所以
<1>处的channel.configureBlocking(false);代码块。也因此,FileChannel 是不能够注册到 Channel 中的,因为它是阻塞的。在
#register(Selector selector, int interestSet)方法的第二个参数,表示一个“interest 集合”,意思是通过 Selector 监听 Channel 时,对哪些( 可以是多个 )事件感兴趣。可以监听四种不同类型的事件:Connect :连接完成事件( TCP 连接 ),仅适用于客户端,对应
SelectionKey.OP_CONNECT。Accept :接受新连接事件,仅适用于服务端,对应
SelectionKey.OP_ACCEPT。Read :读事件,适用于两端,对应
SelectionKey.OP_READ,表示 Buffer 可读。Write :写时间,适用于两端,对应
SelectionKey.OP_WRITE,表示 Buffer 可写。
Channel 触发了一个事件,意思是该事件已经就绪:
一个 Client Channel Channel 成功连接到另一个服务器,称为“连接就绪”。
一个 Server Socket Channel 准备好接收新进入的连接,称为“接收就绪”。
一个有数据可读的 Channel ,可以说是“读就绪”。
一个等待写数据的 Channel ,可以说是“写就绪”。
因为 Selector 可以对 Channel 的多个事件感兴趣,所以在我们想要注册 Channel 的多个事件到 Selector 中时,可以使用或运算 | 来组合多个事件。示例代码如下:
int interestSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE;实际使用时,我们会有改变 Selector 对 Channel 感兴趣的事件集合,可以通过再次调用 #register(Selector selector, int interestSet) 方法来进行变更。示例代码如下:
channel.register(selector, SelectionKey.OP_READ);
channel.register(selector, SelectionKey.OP_READ | SelectionKey.OP_WRITE);初始时,Selector 仅对 Channel 的
SelectionKey.OP_READ事件感兴趣。修改后,Selector 仅对 Channel 的
SelectionKey.OP_READ和SelectionKey.OP_WRITE)事件都感兴趣。
在 Netty 中,`SelectionKey` 的
interestOps()方法用于获取当前注册到选择器(Selector)上的通道(Channel)所感兴趣的事件集合。这些事件包括读、写、连接和接受等。了解通道感兴趣的事件对于实现高效的 I/O 多路复用非常重要。以下是
interestOps()方法的一些用途:1. 事件驱动编程:Netty 采用事件驱动编程模型,通过监听通道感兴趣的事件来实现非阻塞 I/O 操作。当某个事件发生时,选择器会通知相应的
SelectionKey,从而触发相应的事件处理器(ChannelHandler)执行。2. 优化资源利用:通过设置感兴趣的事件集合,可以让选择器只关注必要的事件,从而减少不必要的 I/O 操作和系统调用,提高资源利用率。
3. 动态调整事件监听:在运行时,可以根据需要动态地调整通道感兴趣的事件集合。例如,当一个连接建立完成后,可以将感兴趣的事件从
OP_CONNECT切换到OP_READ和OP_WRITE。4. 处理半包和粘包问题:在某些协议中,可能会出现半包(部分数据)和粘包(多个小数据包合并成一个大数据包)的问题。通过设置合适的感兴趣事件,可以在事件处理器中实现自定义的编解码逻辑,从而解决这些问题。
5. 优雅地关闭连接:当需要关闭一个连接时,可以通过取消注册感兴趣的事件来实现。这样,选择器将不再关注该通道的事件,从而优雅地关闭连接。
总之,`interestOps()` 方法在 Netty 中用于获取通道感兴趣的事件集合,这对于实现高效的事件驱动编程、优化资源利用、动态调整事件监听、处理半包和粘包问题以及优雅地关闭连接等方面都具有重要意义。
在Java NIO(Non-blocking I/O)的上下文中,“感兴趣”是指一个
SelectableChannel(如ServerSocketChannel或SocketChannel)对于特定类型的I/O操作(如读、写、连接或接受连接)是否设置了监听。当一个SelectableChannel被注册到一个Selector上时,会生成一个SelectionKey,这个SelectionKey记录了该通道对哪些类型的I/O操作感兴趣。例如,当你注册一个
ServerSocketChannel到一个Selector上,并希望接收新的客户端连接时,你会设置SelectionKey.OP_ACCEPT标志。这意味着你对该通道上的新连接事件感兴趣。同样地,如果你想监听一个已建立连接的SocketChannel上的读事件,你可以设置SelectionKey.OP_READ标志。这里的关键概念是“感兴趣的事件”,指的是你想让
Selector监控的事件类型。当一个事件发生时,Selector会通知你。例如,如果一个客户端尝试连接到服务器,而服务器的ServerSocketChannel对SelectionKey.OP_ACCEPT事件感兴趣,那么Selector就会检测到这个事件并将其标记为就绪。下面是
SelectionKey中定义的一些常量,它们表示不同的事件类型:
SelectionKey.OP_ACCEPT: 用于ServerSocketChannel,表示对接受新连接感兴趣。
SelectionKey.OP_CONNECT: 用于SocketChannel,表示对完成连接过程感兴趣。
SelectionKey.OP_READ: 表示对读操作感兴趣。
SelectionKey.OP_WRITE: 表示对写操作感兴趣。当你注册一个通道时,你可以指定一个或多个这些事件的组合,例如:
channel.register(selector, SelectionKey.OP_READ | SelectionKey.OP_WRITE);在这个例子中,你告诉
Selector你对该通道上的读和写事件都感兴趣。然后,你可以通过调用SelectionKey.interestOps()方法来获取当前感兴趣的事件集合,或者使用SelectionKey.readyOps()方法来检查哪些事件已经准备就绪。通过使用位运算符(如
&),你可以检查某个特定事件是否包含在感兴趣的事件集合中。例如:int interestSet = key.interestOps(); boolean isInterestedInRead = (interestSet & SelectionKey.OP_READ) != 0; boolean isInterestedInWrite = (interestSet & SelectionKey.OP_WRITE) != 0;这里,
isInterestedInRead和isInterestedInWrite分别表示通道是否对读和写事件感兴趣。如果某个事件的标志位被设置,则相应的布尔值将是true,否则为false。
5. SelectionKey 类
上一小节, 当我们调用 Channel 的 #register(...) 方法,向 Selector 注册一个 Channel 后,会返回一个 SelectionKey 对象。那么 SelectionKey 是什么呢?SelectionKey 在 java.nio.channels 包下,被定义成一个抽象类,表示一个 Channel 和一个 Selector 的注册关系,包含如下内容:
interest set :感兴趣的事件集合。
ready set :就绪的事件集合。
Channel
Selector
attachment :可选的附加对象。
5.1 interest set
通过调用 #interestOps() 方法,返回感兴趣的事件集合。示例代码如下:
int interestSet = selectionKey.interestOps();
// 判断对哪些事件感兴趣
boolean isInterestedInAccept = interestSet & SelectionKey.OP_ACCEPT != 0;
boolean isInterestedInConnect = interestSet & SelectionKey.OP_CONNECT != 0;
boolean isInterestedInRead = interestSet & SelectionKey.OP_READ != 0;
boolean isInterestedInWrite = interestSet & SelectionKey.OP_WRITE != 0;其中每个事件 Key 在 SelectionKey 中枚举,通过位( bit ) 表示。代码如下:
// SelectionKey.java
public static final int OP_READ = 1 << 0;
public static final int OP_WRITE = 1 << 2;
public static final int OP_CONNECT = 1 << 3;
public static final int OP_ACCEPT = 1 << 4;所以,在上述示例的后半段的代码,可以通过与运算
&来判断是否对指定事件感兴趣。
5.2 ready set
通过调用 #readyOps() 方法,返回就绪的事件集合。示例代码如下:
int readySet = selectionKey.readyOps();
// 判断哪些事件已就绪
selectionKey.isAcceptable();
selectionKey.isConnectable();
selectionKey.isReadable();
selectionKey.isWritable();相比 interest set 来说,ready set 已经内置了判断事件的方法。代码如下:
// SelectionKey.java
public final boolean isReadable() {
return (readyOps() & OP_READ) != 0;
}
public final boolean isWritable() {
return (readyOps() & OP_WRITE) != 0;
}
public final boolean isConnectable() {
return (readyOps() & OP_CONNECT) != 0;
}
public final boolean isAcceptable() {
return (readyOps() & OP_ACCEPT) != 0;
}5.3 attachment
通过调用 #attach(Object ob) 方法,可以向 SelectionKey 添加附加对象;通过调用 #attachment() 方法,可以获得 SelectionKey 获得附加对象。示例代码如下:
selectionKey.attach(theObject);
Object attachedObj = selectionKey.attachment();又获得在注册时,直接添加附加对象。示例代码如下:
SelectionKey key = channel.register(selector, SelectionKey.OP_READ, theObject);6. 通过 Selector 选择 Channel
在 Selector 中,提供三种类型的选择( select )方法,返回当前有感兴趣事件准备就绪的 Channel 数量:
// Selector.java
// 阻塞到至少有一个 Channel 在你注册的事件上就绪了。
public abstract int select() throws IOException;
// 在 `#select()` 方法的基础上,增加超时机制。
public abstract int select(long timeout) throws IOException;
// 和 `#select()` 方法不同,立即返回数量,而不阻塞。
public abstract int selectNow() throws IOException;有一点非常需要注意:select 方法返回的
int值,表示有多少 Channel 已经就绪。亦即,自上次调用 select 方法后有多少 Channel 变成就绪状态。如果调用 select 方法,因为有一个 Channel 变成就绪状态则返回了 1 ;若再次调用 select 方法,如果另一个 Channel 就绪了,它会再次返回1。如果对第一个就绪的 Channel 没有做任何操作,现在就有两个就绪的 Channel ,但在每次 select 方法调用之间,只有一个 Channel 就绪了,所以才返回 1。
7. 获取可操作的 Channel
一旦调用了 select 方法,并且返回值表明有一个或更多个 Channel 就绪了,然后可以通过调用Selector 的 #selectedKeys() 方法,访问“已选择键集( selected key set )”中的就绪 Channel 。示例代码所示:
Set selectedKeys = selector.selectedKeys();注意,当有新增就绪的 Channel ,需要先调用 select 方法,才会添加到“已选择键集( selected key set )”中。否则,我们直接调用
#selectedKeys()方法,是无法获得它们对应的 SelectionKey 们。
8. 唤醒 Selector 选择
某个线程调用 #select() 方法后,发生阻塞了,即使没有通道已经就绪,也有办法让其从 #select() 方法返回。
只要让其它线程在第一个线程调用
select()方法的那个 Selector 对象上,调用该 Selector 的#wakeup()方法,进行唤醒该 Selector 即可。那么,阻塞在
#select()方法上的线程,会立马返回。
Selector 的
#select(long timeout)方法,若未超时的情况下,也可以满足上述方式。
注意,如果有其它线程调用了 #wakeup() 方法,但当前没有线程阻塞在 #select() 方法上,下个调用 #select() 方法的线程会立即被唤醒。😈 有点神奇。
9. 关闭 Selector
当我们不再使用 Selector 时,可以调用 Selector 的 #close() 方法,将它进行关闭。
Selector 相关的所有 SelectionKey 都会失效。
Selector 相关的所有 Channel 并不会关闭。
注意,此时若有线程阻塞在 #select() 方法上,也会被唤醒返回。
10. 简单 Selector 示例
如下是一个简单的 Selector 示例,创建一个 Selector ,并将一个 Channel注册到这个 Selector上( Channel 的初始化过程略去 ),然后持续轮询这个 Selector 的四种事件( 接受,连接,读,写 )是否就绪。代码如下:
本代码取自 《Java NIO系列教程(六) Selector》 提供的示例,实际生产环境下并非这样的代码。🙂 最佳的实践,我们将在 Netty 中看到。
// 创建 Selector
Selector selector = Selector.open();
// 注册 Channel 到 Selector 中
channel.configureBlocking(false);
SelectionKey key = channel.register(selector, SelectionKey.OP_READ);
while (true) {
// 通过 Selector 选择 Channel
int readyChannels = selector.select();
if (readyChannels == 0) {
continue;
}
// 获得可操作的 Channel
Set selectedKeys = selector.selectedKeys();
// 遍历 SelectionKey 数组
Iterator<SelectionKey> keyIterator = selectedKeys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
// a connection was accepted by a ServerSocketChannel.
} else if (key.isConnectable()) {
// a connection was established with a remote server.
} else if (key.isReadable()) {
// a channel is ready for reading
} else if (key.isWritable()) {
// a channel is ready for writing
}
// 移除
keyIterator.remove(); // <1>
}
}注意, 在每次迭代时, 我们都调用
keyIterator.remove()代码块,将这个 key 从迭代器中删除。因为
#select()方法仅仅是简单地将就绪的 Channel 对应的 SelectionKey 放到 selected keys 集合中。因此,如果我们从 selected keys 集合中,获取到一个 key ,但是没有将它删除,那么下一次
#select时, 这个 SelectionKey 还在 selectedKeys 中.
参考文章如下: