Lucene是一个开源的全文搜索引擎库,提供了强大的全文检索功能。在Lucene中,
FastVectorHighlighter是一个用于文本高亮的工具类,它能够根据搜索结果中的关键词对文本进行高亮显示。本文将深入探讨FastVectorHighlighter的高亮算法实现。FastVectorHighlighter简介
FastVectorHighlighter是Lucene中用于高亮显示搜索结果的关键类之一。它依赖于字段的词汇向量(Term Vectors)来快速定位和提取关键词。词汇向量是一种存储文档中每个词及其位置信息的索引结构,这使得FastVectorHighlighter能够高效地进行高亮处理。高亮算法实现步骤
构建词汇向量:首先,需要为需要高亮的字段构建词汇向量。这一步通常在索引阶段完成。
搜索并获取结果:执行搜索操作,获取包含关键词的文档列表。
提取关键词:对于每个文档,使用
FastVectorHighlighter提取出包含在搜索查询中的关键词。生成高亮片段:根据提取出的关键词,生成高亮显示的文本片段。
返回高亮结果:将生成的高亮片段返回给用户。
关键代码解析
以下是
FastVectorHighlighter中一些关键方法的代码解析:构建词汇向量
public void setFieldMatcher(FieldMatcher matcher) { this.fieldMatcher = matcher; } public void setFragmentScorer(FragmentScorer fragmentScorer) { this.fragmentScorer = fragmentScorer; }在初始化
FastVectorHighlighter时,可以设置字段匹配器和片段评分器。字段匹配器用于确定哪些字段需要进行高亮处理,而片段评分器则用于评估生成的片段的质量。提取关键词
public Highlighter getHighlighter(String fieldName, Query query) throws IOException { QueryScorer scorer = new QueryScorer(query, fieldName); return new Highlighter(scorer); }
getHighlighter方法用于创建一个Highlighter对象,该对象将根据给定的查询和字段名提取关键词。生成高亮片段
public String getBestFragment(TokenStream tokenStream, String text, int startOffset, int endOffset) throws IOException { return highlighter.getBestFragment(tokenStream, text, startOffset, endOffset); }
getBestFragment方法用于生成包含关键词的高亮文本片段。它接受一个TokenStream对象,该对象表示文本的分词流,以及文本的起始和结束偏移量。性能优化
FastVectorHighlighter的性能优化主要体现在以下几个方面:
词汇向量的使用:通过预先构建词汇向量,
FastVectorHighlighter能够在搜索阶段快速定位关键词,避免了逐词扫描的低效操作。缓存机制:
FastVectorHighlighter内部使用了缓存机制,对于重复的高亮请求,可以直接从缓存中获取结果,减少了计算开销。并行处理:在多核处理器环境下,
FastVectorHighlighter可以并行处理多个文档的高亮请求,提高了整体处理速度。总结
FastVectorHighlighter是Lucene中实现高效文本高亮的关键组件之一。通过利用词汇向量和缓存机制,它能够在保证高亮质量的同时,显著提升处理性能。深入理解其算法实现和性能优化策略,有助于更好地应用和扩展Lucene的高亮功能。
背景
在上一篇文章中,我们分析了Highlighter高亮实现方案,遗留了两个问题:
Highlighter不适用于大文档,因为它是通过走一遍分词器,遍历token寻找匹配关键字,效率比较低。
Highlighter最后会对首尾相连的片段进行合并,而拼接的可能是不包含关键字的片段,导致可能整体看起来相关性被稀释。
问题1,本质就是需要解决term匹配的性能问题,幸运的是,在构建索引文件的时候,其实已经有了每个字段中的term的相关信息,不需要再进行分词遍历了。
问题2,我们需要对高亮分片裁剪,对于Highlighter的结果1 “The goal of Apache <b>Lucene</b> is to provide”,可以裁剪成“Apache <b>Lucene</b>”。
Lucene推出的第二个高亮解决方案FastVectorHighlighter就是为了解决这两个问题(准确来说是部分场景解决),既然FastVectorHighlighter已经可以解决这两个问题,为什么Lucene后面还推出了UnifiedHighlighter?这就需要我们深入理解下FastVectorHighlighter的实现,看它是如何解决Highlighter的两个问题,以及它自身又存在什么问题。
FastVectorHighlighter使用示例
我们先通过几个例子来了解FastVectorHighlighter的使用方式以及它存在的一些问题。
下面的测试数据来自官网
示例1
public static void main(String[] args) throws IOException, InvalidTokenOffsetsException {
Directory directory = new ByteBuffersDirectory();
StandardAnalyzer analyzer = new StandardAnalyzer();
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
// 字段索引类型(以下是词向量数据生成的设置)
FieldType fieldType = new FieldType();
fieldType.setStoreTermVectorPositions(true);
fieldType.setStoreTermVectorOffsets(true);
fieldType.setStoreTermVectors(true);
fieldType.setIndexOptions(IndexOptions.DOCS);
fieldType.setStored(true);
// 测试的数据
Document document = new Document();
document.add(new Field("field0", "Lucene is a search engine library.", fieldType));
indexWriter.addDocument(document);
// 构建查询条件: 字段field0中 包含lucene关键字 或者 同时包含slop距离不超过10的search和library
TermQuery termQuery = new TermQuery(new Term("field0", "lucene"));
BoostQuery boostQuery = new BoostQuery(termQuery, 2);
PhraseQuery phraseQuery = new PhraseQuery(10, "field0", "search", "library");
BooleanQuery booleanQuery = new BooleanQuery.Builder()
.add(boostQuery, BooleanClause.Occur.SHOULD)
.add(phraseQuery, BooleanClause.Occur.SHOULD)
.build();
// margin=5(后面解释这个参数)
SimpleFragListBuilder simpleFragListBuilder = new SimpleFragListBuilder(5);
ScoreOrderFragmentsBuilder scoreOrderFragmentsBuilder = new ScoreOrderFragmentsBuilder(BaseFragmentsBuilder.COLORED_PRE_TAGS, BaseFragmentsBuilder.COLORED_POST_TAGS);
FastVectorHighlighter fastVectorHighlighter = new FastVectorHighlighter(true, true, simpleFragListBuilder, scoreOrderFragmentsBuilder);
// 解析query
FieldQuery fieldQuery = fastVectorHighlighter.getFieldQuery(booleanQuery);
IndexReader reader = DirectoryReader.open(indexWriter);
// docId=0
// fragCharSize=50
// maxNumFragments=10
String[] lucenes = fastVectorHighlighter.getBestFragments(fieldQuery, reader, 0, "field0", 50, 10);
for (String lucene : lucenes) {
System.out.println(lucene);
}
}
好的,这段代码主要创建了一个索引写入器(
IndexWriter),添加了一个包含特定字段的文档,构建了一个复杂的布尔查询(BooleanQuery),然后使用FastVectorHighlighter类来对查询结果进行高亮显示。 下面是对代码的详细解释:
Directory directory = new ByteBuffersDirectory();:创建一个ByteBuffersDirectory对象,它表示索引文件的存储目录。
StandardAnalyzer analyzer = new StandardAnalyzer();:创建一个StandardAnalyzer对象,它是Lucene中的一个标准分词器,用于处理文档的文本内容。
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);:使用创建的分析器配置索引写入器。
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);:初始化索引写入器。设置字段类型(
FieldType)以启用词向量存储。创建一个文档(
Document)并添加一个字段(Field)用于测试。创建一个
TermQuery对象用于搜索包含特定关键词的文档。创建一个
BoostQuery对象以增加TermQuery的权重。创建一个
PhraseQuery对象用于搜索包含特定短语的文档。创建一个
BooleanQuery对象用于组合BoostQuery和PhraseQuery。
SimpleFragListBuilder simpleFragListBuilder = new SimpleFragListBuilder(5);:创建一个SimpleFragListBuilder对象,设置片段(frag)的大小为5。
ScoreOrderFragmentsBuilder scoreOrderFragmentsBuilder = new ScoreOrderFragmentsBuilder(BaseFragmentsBuilder.COLORED_PRE_TAGS, BaseFragmentsBuilder.COLORED_POST_TAGS);:创建一个ScoreOrderFragmentsBuilder对象,设置高亮片段的显示样式为带有颜色的前后标记。
FastVectorHighlighter fastVectorHighlighter = new FastVectorHighlighter(true, true, simpleFragListBuilder, scoreOrderFragmentsBuilder);:创建FastVectorHighlighter对象,设置参数以确保可以对高亮片段进行排序。通过
FastVectorHighlighter对象获取BooleanQuery的FieldQuery对象。通过
DirectoryReader.open(indexWriter);获取索引读取器。通过
fastVectorHighlighter.getBestFragments获取高亮片段的结果,并打印出来。总结来说,这段代码创建一个索引,然后构建了一个查询,再用
FastVectorHighlighter类对查询结果进行高亮显示。
输出:
<b style="background:yellow">Lucene</b> is a <b style="background:lawngreen">search</b> engine <b style="background:lawngreen">library</b>.
注意输出结果中BooleanQuery不同匹配的子query使用不同的颜色高亮。
示例2
把上面的BooleanQuery换成MultiPhraseQuery(注意也替换示例1的34行的变量)
// 查找字段field0中包含search和library间隔不超过10的词组
MultiPhraseQuery multiPhraseQuery = new MultiPhraseQuery.Builder()
.setSlop(5)
.add(new Term[]{new Term("field0", "lucene"), new Term("field0", "search")})
.add(new Term[]{new Term("field0", "search"), new Term("field0", "library")})
.build();
查询条件满足,但是高亮无结果。
示例3
示例1的BooleanQuery换成SpanTermQuery(注意也替换示例1的34行的变量)
// 查找字段field0中包含search和library的slop距离不超过10的词组
SpanTermQuery start = new SpanTermQuery(new Term("field0", "search"));
SpanTermQuery end = new SpanTermQuery(new Term("field0", "library"));
SpanNearQuery spanNearQuery = new SpanNearQuery(new SpanQuery[] {start,end}, 10, false);
查询条件满足,但是高亮无结果。
示例4
示例1中的PhraseQuery的term列表换个顺序
PhraseQuery phraseQuery = new PhraseQuery(10, "field0", "library", "search");输出:
<b style="background:yellow">Lucene</b> is a search engine library.
可以看到满足PhraseQuery查询的search和library没有高亮。
示例5
示例1中的34行的fragCharSize参数从50改成30:
String[] lucenes = fastVectorHighlighter.getBestFragments(fieldQuery, reader, 0, "field0", 30, 10);输出:
<b style="background:yellow">Lucene</b> is a search engine library
可以看到满足条件的子查询PhraseQuery(search, library)没有高亮。
示例6
示例1中的TermQuery改成engine,注意term查询的关键字engine在PhraseQuery词组search和library的中间:
TermQuery termQuery = new TermQuery(new Term("field0", "engine"));输出:
Lucene is a search <b style="background:yellow">engine</b> library.
可以看到满足PhraseQuery查询的search和library没有高亮。
示例总结
从以上所有的示例中,我们可以看出来FastVectorHighlighter存在的一些问题:
示例2和示例3说明了FastVectorHighlighter不支持MultiPhraseQuery和SpanQuery。
示例4说明了FastVectorHighlighter中PhraseQuery是否高亮跟短语词组中的term的定义顺序有关。
示例5说明高亮结果中包含了满足PhraseQuery的词组,但是因为fragCharSize参数的关系没有高亮。
示例6说明了匹配PhraseQuery的词组之间插入匹配的TermQuery之后就不高亮了。
那是什么原因造成了以上这些问题,我们只能从源码中找答案了。
注意:
以下如果没有特殊说明,一些数据结构都以示例1中的Query和Document为例进行说明。
本文源码解析基于Lucene 9.1.0版本。
预备知识
词向量
这里我们不详细说明lucene中词向量的数据结构以及如何生成的。只需要知道它们是什么以及怎么用就行了。
词向量其实就是一组term的集合。索引库的词向量就是索引中所有文档的term的集合。文档的词向量就是特定文档中所有term的集合。同样可以类推文档中某个字段的词向量就是这个字段中term的集合。
词向量数据的生成必须在索引的时候打开示例1中的那些设置。
如下图所示(注意此图非lucene中正式的词向量数据文件格式),此图只是示意图,用来展示词向量及其位置信息。
文档doc1中有两个字段,对于字段field1有词向量(c,e,g),对于term c在field1中出现了两次,分别在第0和第2个位置出现,两个位置出现的起始位置和结束位置分别是0,4和1,5。
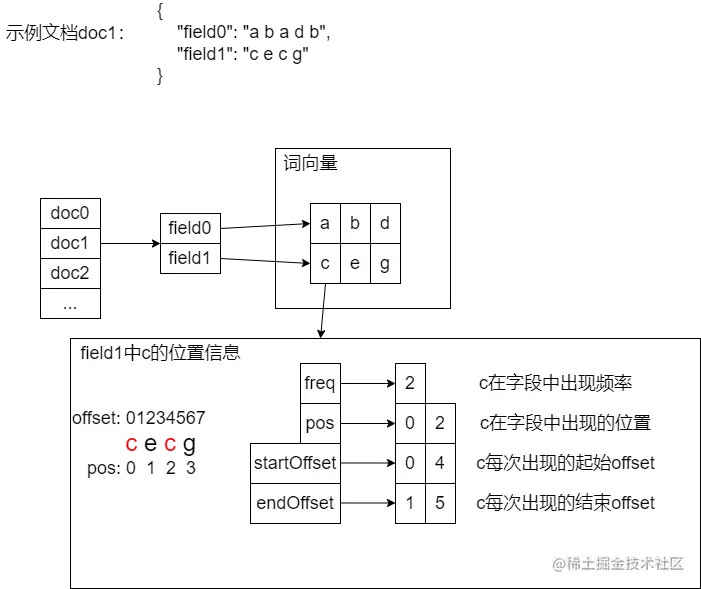
基于词向量及其位置信息就可以不用重新进行分词获取token。从而解决了Highlighter中的问题1。
lucene中通过IndexReader#getTermVectors(int docId)获取指定doc的词向量Fields,Fields#terms(String field)可以获取指定字段的词向量Terms。通过迭代Terms,获取term,根据term可以获取term的位置信息(在字段中出现的频率,position以及offset信息等)。
Query树
在Lucene中Query是可以嵌套Query的,以BooleanQuery为例,BooleanQuery是由多个子Query组成的,而子Query又可以由子Query组成,就构成了Query树。Query树的叶子节点的Query就是不可再分的Query,文本匹配中一般就是TermQuery,PhraseQuery。
BreakIterator
BreakIterator是JDK自带的一个文本处理工具类,用它可以找到特定文本的分割点。BreakIterator有四种不同的实现,分别是按字符分割,按词分割,按句子分割,按行分割,默认是使用按句子分割的。但是这四种分割实现跟语言是相关的,所以不要从字面的意思理解,比如英文不要就以为“.”就是句子的分隔符,其实是“ .”(空格+.)或者"."+换行符才是句子的分隔标记。具体的可以参考JDK官方文档,自己写demo上手试试。
不管是哪种分割实现,我们只需要知道它怎么用,具体来看下BreakIterator提供了哪些接口
// 设置要分割的文本
public void setText(String newText)
{
setText(new StringCharacterIterator(newText));
}
// 交由不同实现类实现,会做一些初始化操作
public abstract void setText(CharacterIterator newText);
// 获取被分割的文本
public abstract CharacterIterator getText();
// 返回当前的offset
public abstract int current();
// 获取第一个分割点,并且把当前位置设置成第一个分割点
public abstract int first();
// 获取最后一个分割点,并且当前位置会设置成最后一个分割点
public abstract int last();
// 获取第n个分割点,如果存在第n个分割点,当前位置会设置成第n个分割点
public abstract int next(int n);
// 获取当前位置的下一个分割点,当前位置会设置成下一个分割点
public abstract int next();
// 获取当前位置的前一个分割点,当前位置会设置成前一个分割点
public abstract int previous();
// 获取offset之后的一个分割点,当前位置会设置成offset的下一个分割点
public abstract int following(int offset);
// 获取offset的前一个分割点,当前位置会设置成offset的前一个分割点
public int preceding(int offset) {
int pos = following(offset);
while (pos >= offset && pos != DONE) {
pos = previous();
}
return pos;
}
// offset是否是一个分割点
public boolean isBoundary(int offset) {
if (offset == 0) {
return true;
}
int boundary = following(offset - 1);
if (boundary == DONE) {
throw new IllegalArgumentException();
}
return boundary == offset;
}BoundaryScanner
FastVectorHighlighter中寻找高亮片段offset的工具类,BoundaryScanner接口有两个方法,分别寻找高亮片段的startOffset和endOffset
public interface BoundaryScanner {
// 以start为起点往前查找,在buffer中寻找高亮分片的起点
public int findStartOffset(StringBuilder buffer, int start);
// 以start为起点往后查找,在buffer中寻找高亮分片的终点
public int findEndOffset(StringBuilder buffer, int start);
}它有两个实现类:
SimpleBoundaryScanner
SimpleBoundaryScanner中有个固定的字符集合,集合中的每个字符都可以作为边界,SimpleBoundaryScanner有两个成员变量
// 最多查找的字符个数
protected int maxScan;
// 可以用来做分界的字符集合
protected Set<Character> boundaryChars;
看高亮片段起点和终点查找方法的实现
@Override
public int findStartOffset(StringBuilder buffer, int start) {
// 如果start参数不合法,则直接返回start
if (start > buffer.length() || start < 1) return start;
int offset, count = maxScan;
// 从start往前查找,最多查找maxScan次
for (offset = start; offset > 0 && count > 0; count--) {
// 找到边界字符,返回边界字符位置+1,可以知道返回的起始offset是不包含边界字符的
if (boundaryChars.contains(buffer.charAt(offset - 1))) return offset;
offset--;
}
// 如果已经找到了buffer的第一个字符,则直接返回0作为起点
if (offset == 0) {
return 0;
}
// 经过maxScan次还没有找到,则返回start
return start;
}
@Override
public int findEndOffset(StringBuilder buffer, int start) {
// 如果start参数不合法,则直接返回start
if (start > buffer.length() || start < 0) return start;
int offset, count = maxScan;
// 从start往后找,最多找maxScan次
for (offset = start; offset < buffer.length() && count > 0; count--) {
// 如果找到边界字符,则返回边界字符所在的位置做为终点
if (boundaryChars.contains(buffer.charAt(offset))) return offset;
offset++;
}
// 经过maxScan次没有找到或者找到buffer的末尾,则返回start。
// 这边为什么没有一个到末尾直接返回末尾作为结束位置的逻辑呢?
return start;
}
BreakIteratorBoundaryScanner
BreakIteratorBoundaryScanner寻找高亮分片的起始位置和结束位置依赖了BreakIterator:
public class BreakIteratorBoundaryScanner implements BoundaryScanner {
final BreakIterator bi;
public BreakIteratorBoundaryScanner(BreakIterator bi) {
this.bi = bi;
}
@Override
public int findStartOffset(StringBuilder buffer, int start) {
// start合法性校验
if (start > buffer.length() || start < 1) return start;
// 只在子串中查找
bi.setText(buffer.substring(0, start));
// bi中的当前位置会定位到最后一个分割点
bi.last();
// 之所以返回最后一个分割点的前一个分割点,
// 是因为最后一个分割点一般就是字符串的末尾,如果只返回最后一个分割点,返回的就是start(子串是以start结束的)
return bi.previous();
}
@Override
public int findEndOffset(StringBuilder buffer, int start) {
// start合法性校验
if (start > buffer.length() || start < 0) return start;
bi.setText(buffer.substring(start));
// 因为bi处理的是start开始的子串,所以真正的位置需要加上start
return bi.next() + start;
}
算法流程
接下来会以我们示例1(官网的例子)来介绍整个FastVectorHighlighter高亮实现流程。
我们用的是StandardAnalyzer分词器,会对所有字母进行小写。
在实现的过程中,FastVectorHighlighter依赖了几个重要的数据结构,为了方便对照观察各个数据结构,我们把文本的position和offset都列出来
+--------+-----------------------------------+
| | 1111111111222222222233333|
| offset|01234567890123456789012345678901234|
+--------+-----------------------------------+
|document|Lucene is a search engine library. |
+--------*-----------------------------------+
|position|0 1 2 3 4 5 |
+--------*-----------------------------------+
step1 解析Query
解析Query做了以下几个事情:
获取query树叶子节点的query集合(TermQuery和PhraseQuery)。
获取query集合中出现的term集合。
扩展PhraseQuery,什么叫扩展PhraseQuery以及为什么需要扩展PhraseQuery后面解释。
构建QueryPhraseMap结构。
解析query的所有逻辑都在FieldQuery中,先看下FieldQuery的成员变量
// 是否需要区分字段,如果不区分字段,则所有的字段共享query解析的结果。
final boolean fieldMatch;
// fieldMatch==true, Map<fieldName,QueryPhraseMap>
// fieldMatch==false, Map<null,QueryPhraseMap>
// 映射了query树的结构
Map<String, QueryPhraseMap> rootMaps = new HashMap<>();
// fieldMatch==true, Map<fieldName,setOfTermsInQueries>
// fieldMatch==false, Map<null,setOfTermsInQueries>
// 保存query中出现的所有的term
Map<String, Set<String>> termSetMap = new HashMap<>();
// 如果query树不同的子query匹配需要用不同的高亮颜色,则会用到这个编码(算法最后一步会介绍)
int termOrPhraseNumber;
解析Query的逻辑都在构造函数中
// query: 检索的query
// reader: 获取词向量
// phraseHighlight: true的话必须是按短语匹配规格处理高亮;false就对词组中的term单独匹配高亮
// fieldMatch: 是否需要区分字段,如果不区分字段,则所有的字段共享query解析的结果。
public FieldQuery(Query query, IndexReader reader, boolean phraseHighlight, boolean fieldMatch)
throws IOException {
this.fieldMatch = fieldMatch;
Set<Query> flatQueries = new LinkedHashSet<>();
// 获取query树叶子节点的query集合,放在flatQueries中
flatten(query, reader, flatQueries, 1f);
// 从所有的flatQueries的query获取term放在termSetMap中
saveTerms(flatQueries, reader);
// 如果有首尾重叠的PhraseQuery则需要扩展一个
Collection<Query> expandQueries = expand(flatQueries);
// 构建QueryPhraseMap结构,映射的整个term前缀树
for (Query flatQuery : expandQueries) {
QueryPhraseMap rootMap = getRootMap(flatQuery);
rootMap.add(flatQuery, reader);
float boost = 1f;
while (flatQuery instanceof BoostQuery) {
BoostQuery bq = (BoostQuery) flatQuery;
flatQuery = bq.getQuery();
boost *= bq.getBoost();
}
// 如果phraseHighlight为false(不进行Phrase级别的匹配),
// 会把Phrase中的所有term当成termquery来匹配,会更新boost
if (!phraseHighlight && flatQuery instanceof PhraseQuery) {
PhraseQuery pq = (PhraseQuery) flatQuery;
if (pq.getTerms().length > 1) {
for (Term term : pq.getTerms()) rootMap.addTerm(term, boost);
}
}
}
}
获取query树叶子节点的query
flatten方法实现了获取所有叶子节点Query的逻辑,flattern方法很长,但是逻辑非常简单,大部分是根据不同的Query递归获取叶子节点query,我们关注两个地方,一个是递归出口(有两处,分别是TermQuery和PhraseQuery),另一个是最后一个注释,不在这个方法中的Query类型都被忽略了,所以这个方法决定了FastVectorHighlighter只支持哪些query,这就是FastVectorHighlighter不支持MultiQuery和SpanQuery的原因,解释了示例问题1
protected void flatten(
Query sourceQuery, IndexReader reader, Collection<Query> flatQueries, float boost)
throws IOException {
while (sourceQuery instanceof BoostQuery) {
BoostQuery bq = (BoostQuery) sourceQuery;
sourceQuery = bq.getQuery();
boost *= bq.getBoost();
}
if (sourceQuery instanceof BooleanQuery) {
BooleanQuery bq = (BooleanQuery) sourceQuery;
for (BooleanClause clause : bq) {
if (!clause.isProhibited()) {
flatten(clause.getQuery(), reader, flatQueries, boost);
}
}
} else if (sourceQuery instanceof DisjunctionMaxQuery) {
DisjunctionMaxQuery dmq = (DisjunctionMaxQuery) sourceQuery;
for (Query query : dmq) {
flatten(query, reader, flatQueries, boost);
}
}
else if (sourceQuery instanceof TermQuery) {
if (boost != 1f) {
sourceQuery = new BoostQuery(sourceQuery, boost);
}
// 递归的出口1
if (!flatQueries.contains(sourceQuery)) flatQueries.add(sourceQuery);
} else if (sourceQuery instanceof SynonymQuery) {
SynonymQuery synQuery = (SynonymQuery) sourceQuery;
for (Term term : synQuery.getTerms()) {
flatten(new TermQuery(term), reader, flatQueries, boost);
}
} else if (sourceQuery instanceof PhraseQuery) {
PhraseQuery pq = (PhraseQuery) sourceQuery;
if (pq.getTerms().length == 1) sourceQuery = new TermQuery(pq.getTerms()[0]);
if (boost != 1f) {
sourceQuery = new BoostQuery(sourceQuery, boost);
}
// 递归的出口2
// 这里我觉得加个判断比较好,如果已经存在相同词组的PhraseQuery,更新slop为大的那个
flatQueries.add(sourceQuery);
} else if (sourceQuery instanceof ConstantScoreQuery) {
final Query q = ((ConstantScoreQuery) sourceQuery).getQuery();
if (q != null) {
flatten(q, reader, flatQueries, boost);
}
} else if (sourceQuery instanceof FunctionScoreQuery) {
final Query q = ((FunctionScoreQuery) sourceQuery).getWrappedQuery();
if (q != null) {
flatten(q, reader, flatQueries, boost);
}
} else if (reader != null) {
Query query = sourceQuery;
Query rewritten;
if (sourceQuery instanceof MultiTermQuery) {
rewritten =
new MultiTermQuery.TopTermsScoringBooleanQueryRewrite(MAX_MTQ_TERMS)
.rewrite(reader, (MultiTermQuery) query);
} else {
rewritten = query.rewrite(reader);
}
if (rewritten != query) {
flatten(rewritten, reader, flatQueries, boost);
}
}
// 其他的query类型都被忽略(示例问题1的原因)
// else discard queries
}
获取query集合中出现的term集合
// 从flatQueries中获取所有的term
void saveTerms(Collection<Query> flatQueries, IndexReader reader) throws IOException {
for (Query query : flatQueries) {
while (query instanceof BoostQuery) {
query = ((BoostQuery) query).getQuery();
}
Set<String> termSet = getTermSet(query);
if (query instanceof TermQuery) termSet.add(((TermQuery) query).getTerm().text());
else if (query instanceof PhraseQuery) {
for (Term term : ((PhraseQuery) query).getTerms()) termSet.add(term.text());
} // MultiTermQuery 需要做query改写来获取term
else if (query instanceof MultiTermQuery && reader != null) {
BooleanQuery mtqTerms = (BooleanQuery) query.rewrite(reader);
for (BooleanClause clause : mtqTerms) {
termSet.add(((TermQuery) clause.getQuery()).getTerm().text());
}
} else
throw new RuntimeException("query \"" + query.toString() + "\" must be flatten first.");
}
}
// 获取query中字段对应的term集合
private Set<String> getTermSet(Query query) {
String key = getKey(query);
Set<String> set = termSetMap.get(key);
if (set == null) {
set = new HashSet<>();
termSetMap.put(key, set);
}
return set;
}
// 获取Query中的字段名,因为调用此方法之前,已经调用flattern方法,所以Query都是叶子query,都是属于一个字段的。
private String getKey(Query query) {
// 如果没有指定字段名,统一会null作为key,也就是所有字段共享最终的term集合
if (!fieldMatch) return null;
while (query instanceof BoostQuery) {
query = ((BoostQuery) query).getQuery();
}
// TermQuery直接获取term的字段名
if (query instanceof TermQuery) return ((TermQuery) query).getTerm().field();
// PhraseQuery中的多个子Term肯定都是相同字段的,所以从第一个term中取就行
else if (query instanceof PhraseQuery) {
PhraseQuery pq = (PhraseQuery) query;
Term[] terms = pq.getTerms();
return terms[0].field();
} else if (query instanceof MultiTermQuery) {
return ((MultiTermQuery) query).getField();
} else throw new RuntimeException("query \"" + query.toString() + "\" must be flatten first.");
}
扩展PhraseQuery
为什么需要扩展PhraseQuery,我们举个例子就清楚了。
对于文本“a b c”,PhraseQuery(a,b)和PhraseQuery(b,c)的短语匹配,则在匹配了a和b之后,c就无法匹配,从而导致c不会被高亮。所以发现PhraseQuery(a,b)和PhraseQuery(b,c)有重叠,则额外扩展一个PhraseQuery(a,b,c)的短语匹配,在匹配的时候选最长短语匹配就能把(a,b,c)都高亮
Collection<Query> expand(Collection<Query> flatQueries) {
Set<Query> expandQueries = new LinkedHashSet<>();
for (Iterator<Query> i = flatQueries.iterator(); i.hasNext(); ) {
Query query = i.next();
i.remove();
expandQueries.add(query);
float queryBoost = 1f;
while (query instanceof BoostQuery) {
BoostQuery bq = (BoostQuery) query;
queryBoost *= bq.getBoost();
query = bq.getQuery();
}
// 只处理PhraseQuery
if (!(query instanceof PhraseQuery)) continue;
// 暴力遍历判断是否首尾相重叠
for (Iterator<Query> j = flatQueries.iterator(); j.hasNext(); ) {
Query qj = j.next();
float qjBoost = 1f;
while (qj instanceof BoostQuery) {
BoostQuery bq = (BoostQuery) qj;
qjBoost *= bq.getBoost();
qj = bq.getQuery();
}
if (!(qj instanceof PhraseQuery)) continue;
// 判断两个PhraseQuery是否首尾重叠
checkOverlap(expandQueries, (PhraseQuery) query, queryBoost, (PhraseQuery) qj, qjBoost);
}
}
return expandQueries;
}
/*
* Check if PhraseQuery A and B have overlapped part.
*
* ex1) A="a b", B="b c" => overlap; expandQueries={"a b c"}
* ex2) A="b c", B="a b" => overlap; expandQueries={"a b c"}
* ex3) A="a b", B="c d" => no overlap; expandQueries={}
*/
private void checkOverlap(
Collection<Query> expandQueries, PhraseQuery a, float aBoost, PhraseQuery b, float bBoost) {
// slop不相同,则直接返回
if (a.getSlop() != b.getSlop()) return;
Term[] ats = a.getTerms();
Term[] bts = b.getTerms();
// 如果指定了字段名,则两个PhraseQuery的字段必须相同
if (fieldMatch && !ats[0].field().equals(bts[0].field())) return;
// 判断是否a重叠b
checkOverlap(expandQueries, ats, bts, a.getSlop(), aBoost);
// 判断是否b重叠a
checkOverlap(expandQueries, bts, ats, b.getSlop(), bBoost);
}
/*
* 看注释,非常清楚。
*
* ex1) src="a b", dest="c d" => no overlap
* ex2) src="a b", dest="a b c" => no overlap
* ex3) src="a b", dest="b c" => overlap; expandQueries={"a b c"}
* ex4) src="a b c", dest="b c d" => overlap; expandQueries={"a b c d"}
* ex5) src="a b c", dest="b c" => no overlap
* ex6) src="a b c", dest="b" => no overlap
* ex7) src="a a a a", dest="a a a" => overlap;
* expandQueries={"a a a a a","a a a a a a"}
* ex8) src="a b c d", dest="b c" => no overlap
*/
private void checkOverlap(
Collection<Query> expandQueries, Term[] src, Term[] dest, int slop, float boost) {
// 从src的第二个term开始遍历
for (int i = 1; i < src.length; i++) {
boolean overlap = true;
for (int j = i; j < src.length; j++) {
// 如果j - i >= dest.length,则说明dest被包含在src中了
// 第二个判断条件就是从src的第i个开始的子term集合是否是dest的前缀
if ((j - i) < dest.length && !src[j].text().equals(dest[j - i].text())) {
overlap = false;
break;
}
}
// 如果有重叠,则增加一个扩展的PhraseQuery
if (overlap && src.length - i < dest.length) {
PhraseQuery.Builder pqBuilder = new PhraseQuery.Builder();
for (Term srcTerm : src) pqBuilder.add(srcTerm);
for (int k = src.length - i; k < dest.length; k++) {
pqBuilder.add(new Term(src[0].field(), dest[k].text()));
}
pqBuilder.setSlop(slop);
Query pq = pqBuilder.build();
if (boost != 1f) {
pq = new BoostQuery(pq, 1f);
}
if (!expandQueries.contains(pq)) expandQueries.add(pq);
}
}
}
构建QueryPhraseMap结构
QueryPhraseMap是FieldQuery的内部类,它存储的是term的前缀树。
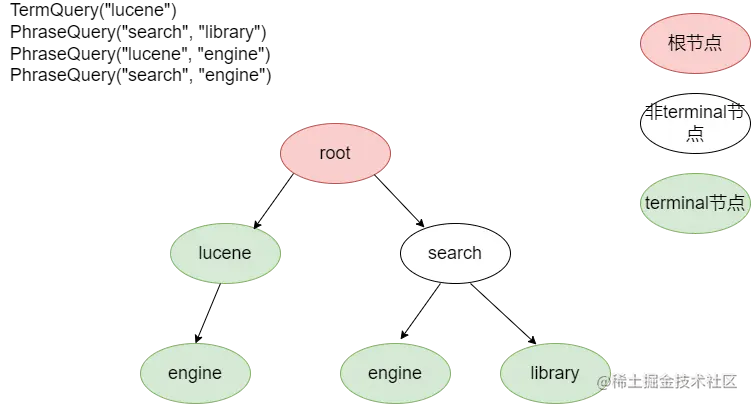
如下图所示,有四个query,它们构成的term前缀树,PhraseQuery("search", "library")和PhraseQuery("search", "engine")共享“search”这个前缀term,因为存在TermQuery("lucene"),所以“lucene”这个节点是terminal节点,并且它和PhraseQuery("lucene", "engine")共享“lucene”这个前缀term。
QueryPhraseMap的成员变量
// 是否是query中的最后一个term
boolean terminal;
// (terminal == true && phraseHighlight == true)才有效,表示的是phraseQuery中的slop
int slop;
// terminal == true 才有效
float boost;
// terminal == true 才有效,
// 如果query树不同的子query匹配需要用不同的高亮颜色,则会用到这个编码(算法最后一步会介绍)
int termOrPhraseNumber;
FieldQuery fieldQuery;
// 下一个term的QueryPhraseMap结构
Map<String, QueryPhraseMap> subMap = new HashMap<>();
如果是TermQuery,则它的subMap是空,并且terminal=true,表示没有后续的term。如果是PhraseQuery,则PhraseQuery中的第一个term的QueryPhraseMap结构中的subMap就是第二个term的QueryPhraseMap结构,直到最后一个term的subMap是空,并且terminal=true,表示没有后续的term。
QueryPhraseMap中的核心方法
void addTerm(Term term, float boost) {
QueryPhraseMap map = getOrNewMap(subMap, term.text());
map.markTerminal(boost);
}
// 如果subMap中不存在term的QueryPhraseMap结构,则创建
private QueryPhraseMap getOrNewMap(Map<String, QueryPhraseMap> subMap, String term) {
QueryPhraseMap map = subMap.get(term);
if (map == null) {
map = new QueryPhraseMap(fieldQuery);
subMap.put(term, map);
}
return map;
}
void add(Query query, IndexReader reader) {
float boost = 1f;
// 找出BoostQuery中最底层的query
while (query instanceof BoostQuery) {
BoostQuery bq = (BoostQuery) query;
query = bq.getQuery();
boost = bq.getBoost(); // 这里感觉是个bug,应该是boost *= bq.getBoost();
}
// 如果是个TermQuery就添加term
if (query instanceof TermQuery) {
addTerm(((TermQuery) query).getTerm(), boost);
} else if (query instanceof PhraseQuery) {
PhraseQuery pq = (PhraseQuery) query;
Term[] terms = pq.getTerms();
Map<String, QueryPhraseMap> map = subMap;
QueryPhraseMap qpm = null;
// 把PhraseQuery中的每个term都连起来
// 注意注意!!!这里是按照PhraseQuery中term的定义顺序处理的,这是造成示例问题2的原因之一
for (Term term : terms) {
qpm = getOrNewMap(map, term.text());
map = qpm.subMap;
}
// 最后一个term添加结束标记
qpm.markTerminal(pq.getSlop(), boost);
} else
throw new RuntimeException("query \"" + query.toString() + "\" must be flatten first.");
}
// 获取子term的QueryPhraseMap结构
public QueryPhraseMap getTermMap(String term) {
return subMap.get(term);
}
private void markTerminal(float boost) {
markTerminal(0, boost);
}
private void markTerminal(int slop, float boost) {
this.terminal = true;
this.slop = slop;
this.boost = boost;
this.termOrPhraseNumber = fieldQuery.nextTermOrPhraseNumber();
}
public QueryPhraseMap searchPhrase(final List<TermInfo> phraseCandidate) {
QueryPhraseMap currMap = this;
for (TermInfo ti : phraseCandidate) {
currMap = currMap.subMap.get(ti.getText());
if (currMap == null) return null;
}
return currMap.isValidTermOrPhrase(phraseCandidate) ? currMap : null;
}
public boolean isValidTermOrPhrase(final List<TermInfo> phraseCandidate) {
// 如果不是terminal的肯定不是合法的
if (!terminal) return false;
// 如果是单term的PraseQuery肯定是合法的
if (phraseCandidate.size() == 1) return true;
// phraseCandidate中的term已经是按position排序的。
// 计算PhraseQuery中两两term之间的距离是否满足slop的要求
int pos = phraseCandidate.get(0).getPosition();
for (int i = 1; i < phraseCandidate.size(); i++) {
int nextPos = phraseCandidate.get(i).getPosition();
if (Math.abs(nextPos - pos - 1) > slop) return false;
pos = nextPos;
}
return true;
}
}
构建QueryPhraseMap结构的实现在FieldQuery的构造函数中,这边我觉得可以抽一个方法出来
public FieldQuery(Query query, IndexReader reader, boolean phraseHighlight, boolean fieldMatch)
throws IOException {
this.fieldMatch = fieldMatch;
Set<Query> flatQueries = new LinkedHashSet<>();
// 获取query树叶子节点的query集合,放在flatQueries中
flatten(query, reader, flatQueries, 1f);
// 从所有的flatQueries的query获取term放在termSetMap中
saveTerms(flatQueries, reader);
// 如果有首尾重叠的PhraseQuery则需要扩展一个
Collection<Query> expandQueries = expand(flatQueries);
// 构建QueryPhraseMap结构,映射的整个Query树
for (Query flatQuery : expandQueries) {
QueryPhraseMap rootMap = getRootMap(flatQuery);
rootMap.add(flatQuery, reader);
float boost = 1f;
while (flatQuery instanceof BoostQuery) {
BoostQuery bq = (BoostQuery) flatQuery;
flatQuery = bq.getQuery();
boost *= bq.getBoost();
}
// 如果phraseHighlight为false(不进行Phrase级别的匹配),
// 会把Phrase中的所有term当成TermQuery来匹配,会更新boost
// 这里需要注意,已有的Phrase的term的级联的QueryPhraseMap结构还在,只是第一个term的QueryPhraseMap中terminal会更新为true,让subMap失效
if (!phraseHighlight && flatQuery instanceof PhraseQuery) {
PhraseQuery pq = (PhraseQuery) flatQuery;
if (pq.getTerms().length > 1) {
for (Term term : pq.getTerms()) rootMap.addTerm(term, boost);
}
}
}
}
// 获取query字段对应的QueryPhraseMap结构
QueryPhraseMap getRootMap(Query query) {
String key = getKey(query);
QueryPhraseMap map = rootMaps.get(key);
if (map == null) {
map = new QueryPhraseMap(this);
rootMaps.put(key, map);
}
return map;
}
我们看一下示例1中最后的QueryPhraseMap结构:
如果phraseHighlight=true