背景介绍
在搜索引擎中,一般对于检索出来的相关文档会对query中的关键字进行高亮,借以直观地表示引擎检索结果的相关性。如下图所示,我们在Google中搜索“lucene engine”,搜索的结果列表中的摘要对query词中关键字的匹配进行了红色高亮表示。这种高亮的功能在引擎背后到底是怎么实现的,这就是我们接下来要介绍的内容。
在继续往下面看之前,先想想如果要自己来设计高亮功能的实现,应该要怎么做?
比较直接的想法是遍历检索返回的文档,寻找文档和query中的匹配的关键字进行高亮,最后把关键字匹配个数比较多的某几个片段作为摘要展示,关键字匹配比较多的片段理论上是更能体现相关性的。
对于我们这个直接的想法具体实现需要哪些步骤呢?
寻找匹配项
对匹配项进行高亮
裁剪高亮的片段
寻找匹配个数比较多的某几个片段
而Lucene中实现高亮要解决的主要问题还真就这四个问题!
摘要
Lucene中有三种对搜索结果进行关键字高亮的实现方式(Highlighter,FastVectorHighlighter,UnifiedHighlighter),我会按照它们在Lucene中出现的顺序分为三篇来一一介绍。今天先介绍出现最早的一种实现:Highlighter实现。
Highlighter是lucene中最早提供的高亮实现方式。Highlighter的工作机制依赖了四大组件Fragmenter(分片器),Encoder(编码器),Scorer(打分器)以及Formatter(格式化器)。使用这四大组件刚好可以解决我们上面提出的要实现高亮功能的问题。
Fragmenter是用来决定每个高亮片段的长度。
Encoder支持对高亮片段的内容进行转义。
Scorer对每个高亮片段打分,最后的结果是按分数排序的。
Formatter是怎么高亮(加粗还是标颜色等)匹配的关键字。
至于这四大组件是怎么配合一起工作完成高亮功能我们后面会详细介绍。
注意:本文源码解析基于Lucene 9.1.0版本。
Highlighter使用示例
在正式分析实现之前,先看个Highlighter使用的例子,知道Highlighter是怎么用的:
public class HighlighterDemo {
public static void main(String[] args) throws IOException, InvalidTokenOffsetsException {
// Lucene内置的标准分词器
StandardAnalyzer analyzer = new StandardAnalyzer();
// 搜索field0中匹配短语(lucene search)且slop不超过1的文档
PhraseQuery phraseQuery = new PhraseQuery(1, "field0", "lucene", "search");
// Highlighter四大组件:formatter,encoder,scorer,fragmenter
SimpleHTMLFormatter formatter = new SimpleHTMLFormatter();
DefaultEncoder encoder = new DefaultEncoder();
QueryTermScorer scorer = new QueryTermScorer(phraseQuery);
Highlighter highlighter = new Highlighter(formatter, encoder, scorer);
// 设置每个高亮分片的最大长度为10(字符个数)
SimpleFragmenter fragmenter = new SimpleFragmenter(10);
highlighter.setTextFragmenter(fragmenter);
// 寻找最多5个高亮分片
String[] fragments = highlighter.getBestFragments(analyzer, "field0", "The goal of Apache Lucene is to provide world class search capabilities.", 5);
for(String fragment: fragments) {
System.out.println(fragment);
}
}
}
这段代码是一个Java程序的主方法,其中使用了Lucene库来创建一个短语查询,并使用高亮器(Highlighter)突出显示查询结果中的匹配片段。以下是代码的主要步骤和组件解释:
步骤1:创建一个
StandardAnalyzer对象,用于后续的文本分析。步骤2:构建一个
PhraseQuery对象,指定查询的字段和短语。这里的字段是field0,短语是lucene search,1表示允许在两个词之间最多有1个其他词的间隔(slop),用来表示在field0字段中搜索包含lucene和search的文档,并且这两个词之间可以有0或1个其他词。步骤3:创建
Highlighter对象,它是Lucene中的一个工具,用于在搜索结果中对查询词进行高亮显示。Highlighter对象需要几个组件来工作,包括Formatter、Encoder和Scorer。步骤3.1:创建一个
SimpleHTMLFormatter对象。SimpleHTMLFormatter用于定义高亮显示的格式,它可以将匹配的词用<b>和</b>标签包裹,使其在HTML中显示为粗体。步骤3.2:创建一个
DefaultEncoder对象,它负责将HTML实体编码,确保输出的HTML片段是合规的。步骤3.3:创建一个
QueryTermScorer对象。QueryTermScorer允许Highlighter知道哪些词对查询最重要,用来对PhraseQuery中的词进行评分。步骤4:设置
Highlighter对象的文本分片器(TextFragmenter)为SimpleFragmenter对象。SimpleFragmenter用于将文本分割成片段。这里设置每个分片的最大长度为10,意味着Highlighter将尝试分割文本,使得每个分片包含不超过10个字符。步骤5:调用
Highlighter的getBestFragments方法。这个方法将返回最多5个最佳分片,这些分片是根据PhraseQuery在给定文本中的匹配情况确定的。getBestFragments方法需要Analyzer对象(在步骤1中创建的StandardAnalyzer)、字段名(field0)、文本内容(The goal of Apache...)和最大分片数(5)作为参数。步骤6:在
for循环中,遍历并打印出返回的分片数组。每个分片都是文本的一部分,包含lucene search这一短语。System.out.println(fragment);将在控制台显示每个高亮分片。总体来说,这段代码的目的是为了展示如何使用Lucene来进行文本搜索,并通过
Highlighter工具突出显示搜索结果中的关键短语。
输出:
The goal of Apache <B>Lucene</B> is to provide
class <B>search</B>
例子虽然运行起来了,也产生了结果,但是有几个疑问:
我们明明设置了高亮分片的长度最大是10个字符,但是第一个结果远远超出了10字符
我们要高亮的文本明明不满足PhraseQuery的查询条件,那怎么也有高亮结果
带着这两个问题,我们一起进入源码来一探究竟。
预备知识
为了后面一起看源码不卡壳,有几个工具类需要先了解下。
TokenStream
TokenStream是用来列举文本的token(或者叫term)序列的,俗称分词器。
在分词的过程中,我们可以获取每个token内容,在文本中的position信息,offset信息等属性。而token的每一种属性,在Lucene中就是一个Attribute。不同的分词器支持的属性集合不同,具体可以查看对应的分词器介绍,这里我们就不展开了。
在分词执行之前,用户可以使用AttributeSource#addAttribute接口注册感兴趣的属性,TokenStream继承了AttributeSource,用来管理这些用户关注的属性。分词器在运行的过程中(incrementToken方法),每处理一个分词就会记录这些属性,用户就可以获取对应token的属性信息。
使用示例:
public class TokenStreamDemo {
public static void main(String[] args) throws IOException {
// 简单的空白字符分词器
WhitespaceAnalyzer analyzer = new WhitespaceAnalyzer();
TokenStream tokenStream = analyzer.tokenStream("test", "My name is zjc, what's your name.");
// 注册offset属性和term属性
OffsetAttribute offsetAttribute = tokenStream.addAttribute(OffsetAttribute.class);
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
// 准备启动分词器
tokenStream.reset();
// 如果存在下一个分词
while (tokenStream.incrementToken()) {
// incrementToken方法中会为我们感兴趣的属性填充值,
// 所以incrementToken执行之后就可以获取到对应token的属性
String token = charTermAttribute.toString();
int startOffset = offsetAttribute.startOffset();
int endOffset = offsetAttribute.endOffset();
System.out.println(token + ": " + startOffset + ", " + endOffset);
}
}
}
这段代码实现了对文本内容进行分词,并打印出每个词的文本以及它在文本流中的偏移量。
具体来说,代码首先创建了一个
WhitespaceAnalyzer对象,这个分析器根据空白字符来分割文本。接着,使用
tokenStream方法创建了一个TokenStream,传入的参数包括:域的名称(test,这里可以理解为文本的标题或者标识)以及文本内容(My name is zjc, what's your name.)。随后,代码通过
addAttribute方法从TokenStream对象中获取两个属性:OffsetAttribute和CharTermAttribute。OffsetAttribute用来记录每个词在原始文本中的开始和结束位置;CharTermAttribute用来存储每个词的文本内容。获取属性后,
reset方法初始化TokenStream,使其准备好处理第一个词。在
while循环中,incrementToken方法用于获取下一个词。这个方法内部会为OffsetAttribute和CharTermAttribute属性赋值。然后,使用
charTermAttribute.toString()获取当前词的文本内容,并使用offsetAttribute.startOffset()和offsetAttribute.endOffset()获取当前词的开始和结束位置。最后,将这些信息打印出来。
这个循环过程会一直进行,直到
incrementToken方法返回false,表示已经没有更多的词可以处理。总结来说,这段代码向我们展示了Lucene的
TokenStream如何工作,以及如何获取和利用Token的相关属性。这在文本分析、信息检索和自然语言处理等领域非常有用。
输出:
My: 0, 2
name: 3, 7
is: 8, 10
zjc,: 11, 15
what's: 16, 22
your: 23, 27
name.: 28, 33
对于TokenStream,只要知道在分词器执行之前我们可以注册感兴趣的属性,调用incrementToken方法之后,可以获取当前token的这些属性即可。
TokenGroup
TokenGroup是一个token组,包含了一个token或者是多个重叠的token。
一般分词器不会分词出有重叠的token,目前来看只有一种情况会产生重叠的token,那就是同义词,同义词在同一个position会有多个不同的token。
所以通常情况下TokenGroup只有一个token。
注意:是否高亮是以TokenGroup为单位的,如果TokenGroup中的总得分大于0(TokengGroup中包含query中的关键字得分才会大于0),则整组一起高亮。
成员变量:
// 一个组最多有多少个token
private static final int MAX_NUM_TOKENS_PER_GROUP = 50;
// 数组元素是每个token的得分
private float[] scores = new float[MAX_NUM_TOKENS_PER_GROUP];
// 这个组中目前有多少个token
private int numTokens = 0;
// 整个组在文本中的起始位置
private int startOffset = 0;
// 整个组在文本中的结束位置
private int endOffset = 0;
// 整个组的总得分,也是所有token的得分和
private float tot;
// 关键字匹配token在文本中的起始位置
private int matchStartOffset;
// 关键字匹配token在文本中的结束位置
private int matchEndOffset;
// 用来获取当前token的offset信息
private OffsetAttribute offsetAtt;
这段代码定义了一个类中的几个成员变量,它们用于存储和处理文本分析中的一些关键信息。下面是对每个变量的详细解释:
MAX_NUM_TOKENS_PER_GROUP:这是一个静态常量,表示一个组中最多可以有多少个token。在这个例子中,它的值是50。
scores:这是一个浮点数数组,用于存储每个token的得分。数组的长度等于MAX_NUM_TOKENS_PER_GROUP,即50。
numTokens:这是一个整数变量,表示当前组中实际有多少个token。
startOffset:这是一个整数变量,表示整个组在文本中的起始位置。
endOffset:这是一个整数变量,表示整个组在文本中的结束位置。
tot:这是一个浮点数变量,表示整个组的总得分,也是所有token的得分之和。
matchStartOffset:这是一个整数变量,表示关键字匹配token在文本中的起始位置。
matchEndOffset:这是一个整数变量,表示关键字匹配token在文本中的结束位置。
offsetAtt:这是一个OffsetAttribute类型的变量,用于获取当前token的offset信息。OffsetAttribute是Lucene中的一个接口,它提供了获取token在文本中的起始和结束位置的方法。这些变量共同构成了一个用于处理文本分析中token信息的类。通过这些变量,可以方便地获取和处理文本中的token信息,如计算得分、确定位置等。
几个关键方法:
// 构造方法主要是注册了两个分词过程中关注的属性:offset和term
public TokenGroup(TokenStream tokenStream) {
offsetAtt = tokenStream.addAttribute(OffsetAttribute.class);
tokenStream.addAttribute(CharTermAttribute.class);
}
// score是当前token的得分,怎么来的后面会介绍
void addToken(float score) {
if (numTokens < MAX_NUM_TOKENS_PER_GROUP) {
final int termStartOffset = offsetAtt.startOffset();
final int termEndOffset = offsetAtt.endOffset();
// 如果是第一个token
if (numTokens == 0) {
startOffset = matchStartOffset = termStartOffset;
endOffset = matchEndOffset = termEndOffset;
tot += score;
} else {
// 更新整组的起始位置和结束位置
startOffset = Math.min(startOffset, termStartOffset);
endOffset = Math.max(endOffset, termEndOffset);
// score > 0表示token是匹配的token
if (score > 0) {
// 如果是第一个匹配的token
if (tot == 0) {
matchStartOffset = termStartOffset;
matchEndOffset = termEndOffset;
} else {
// 更新匹配token的范围
matchStartOffset = Math.min(matchStartOffset, termStartOffset);
matchEndOffset = Math.max(matchEndOffset, termEndOffset);
}
tot += score;
}
}
scores[numTokens] = score;
numTokens++;
}
}
// 判断当前token是否和组内的其他token重叠
boolean isDistinct() {
return offsetAtt.startOffset() >= endOffset;
}
:
isDistinct方法在TokenGroup类中用于检查当前Token是否与组内已有的Token重叠。具体来说,它检查当前Token的起始偏移量是否大于或等于组内最后一个Token的结束偏移量。如果是,意味着当前Token与组内其他Token不重叠。以下是对代码的详细解释:
boolean isDistinct() { return offsetAtt.startOffset() >= endOffset; }在这个方法中,
offsetAtt.startOffset()代表当前Token的起始偏移量,endOffset是TokenGroup对象中保存的组内最后一个Token的结束偏移量。如果当前Token的起始偏移量大于或等于组内最后一个Token的结束偏移量,那么可以推断出当前Token与组内其他Token没有重叠部分,因此返回true,表示当前Token是独特的(distinct)。这个概念在处理文本分析或信息检索任务时非常有用,例如在确定关键词的范围或处理文档的片段时。通过这种方式,
isDistinct方法提供了一个简单的逻辑来判断新的Token是否应该被添加到当前TokenGroup中,或者是否应该创建一个新的TokenGroup来容纳新的Token。
QueryTermExtractor
QueryTermExtractor实现的功能是从query中获取所有的term,并为每个term生成一个权重。
有两个核心方法
public static WeightedTerm[] getTerms(Query query, boolean prohibited, String fieldName) {
HashSet<WeightedTerm> terms = new HashSet<>();
Predicate<String> fieldSelector = fieldName == null ? f -> true : fieldName::equals;
// 访问器模式遍历query树,获取query树中所有的term并且为term设置权重
query.visit(new BoostedTermExtractor(1, terms, prohibited, fieldSelector));
return terms.toArray(new WeightedTerm[0]);
}
具体看下BoostedTermExtractor
private static class BoostedTermExtractor extends QueryVisitor {
// 初始的权重
final float boost;
// 最后的term集合
final Set<WeightedTerm> terms;
// 要获取的term集合是否包含BooleanQuery中的MUST_NOT字句query中的term
final boolean includeProhibited;
// Query中要遍历的字段
final Predicate<String> fieldSelector;
private BoostedTermExtractor(
float boost,
Set<WeightedTerm> terms,
boolean includeProhibited,
Predicate<String> fieldSelector) {
this.boost = boost;
this.terms = terms;
this.includeProhibited = includeProhibited;
this.fieldSelector = fieldSelector;
}
@Override
public boolean acceptField(String field) {
return fieldSelector.test(field);
}
@Override
public void consumeTerms(Query query, Term... terms) {
// 把遍历到的term加入集合中,boost作为权重
for (Term term : terms) {
this.terms.add(new WeightedTerm(boost, term.text()));
}
}
@Override
public QueryVisitor getSubVisitor(BooleanClause.Occur occur, Query parent) {
if (parent instanceof BoostQuery) {
// 从这里可以看出,除了BoostQuery会修改term权重,其他term都是1
float newboost = boost * ((BoostQuery) parent).getBoost();
return new BoostedTermExtractor(newboost, terms, includeProhibited, fieldSelector);
}
if (occur == BooleanClause.Occur.MUST_NOT && includeProhibited == false) {
return QueryVisitor.EMPTY_VISITOR;
}
return this;
}
}
TextFragment
TextFragment表示一个高亮片段,它没有直接封装高亮文本片段,而是封装了一个文本序列,用起始位置和结束位置表示文本序列中的一段是高亮片段。
我们看下成员变量
// 文本序列,本高亮片段是它的一个子集
CharSequence markedUpText;
// 高亮片段编号
int fragNum;
// 高亮片段在文本序列中的起始位置
int textStartPos;
// 高亮片段在文本序列中的结束位置
int textEndPos;
// 高亮文本片片段的得分
float score;
TextFragment最主要的有三个方法
// 合并两个首尾相接的高亮片段,得分取大的那个
public void merge(TextFragment frag2) {
textEndPos = frag2.textEndPos;
score = Math.max(score, frag2.score);
}
// 判断当前的高亮片段是否紧接着fragment
public boolean follows(TextFragment fragment) {
return textStartPos == fragment.textEndPos;
}
// toString方法就是返回真正的高亮片段
@Override
public String toString() {
return markedUpText.subSequence(textStartPos, textEndPos).toString();
}
四大组件
Highlighter依赖的四大组件各自完成什么功能,以及如何实现的?接下来我们分别看下:
Formatter
格式化器会对找到高亮片段中的匹配的token做格式化,一般是对匹配的token加一些html标签(加粗,加颜色),在html网页中进行突出显示,如我们示例中的在关键字前后分别加上加粗的标签。
Formatter接口中只有一个方法
public interface Formatter {
// 如果tokenGroup的得分大于0,才对originalText进行高亮。
// 具体实现类都是高亮的处理方式不同(加粗,加颜色),是否高亮的判断逻辑都是一样的。
String highlightTerm(String originalText, TokenGroup tokenGroup);
}SimpleHTMLFormatter
SimpleHTMLFormatter定义了匹配token的前置标签和后置标签,默认是加粗处理。
public class SimpleHTMLFormatter implements Formatter {
// 默认加粗处理
private static final String DEFAULT_PRE_TAG = "<B>";
private static final String DEFAULT_POST_TAG = "</B>";
private String preTag;
private String postTag;
public SimpleHTMLFormatter(String preTag, String postTag) {
this.preTag = preTag;
this.postTag = postTag;
}
// 默认构造器就是使用默认的标签
public SimpleHTMLFormatter() {
this(DEFAULT_PRE_TAG, DEFAULT_POST_TAG);
}
@Override
public String highlightTerm(String originalText, TokenGroup tokenGroup) {
// 没有匹配的token,则直接返回原始文本
if (tokenGroup.getTotalScore() <= 0) {
return originalText;
}
// 预置长度,避免StringBuilder的自动扩容
StringBuilder returnBuffer =
new StringBuilder(preTag.length() + originalText.length() + postTag.length());
// 为匹配的token加上前后标签
returnBuffer.append(preTag);
returnBuffer.append(originalText);
returnBuffer.append(postTag);
return returnBuffer.toString();
}
}
GradientFormatter
SimpleHTMLFormatter对所有的高亮片段处理方式一样,并没有考虑每个高亮片段的得分情况。
GradientFormatter根据TokenGroup分数的不同,用不同的颜色进行高亮。
SpanGradientFormatter
SpanGradientFormatter的实现逻辑和GradientFormatter几乎一样,只不过它高亮颜色使用的是span标签,对所有浏览器都适用。
Encoder
在目前的版本中有两个编码器DefaultEncoder和SimpleHTMLEncoder。
DefaultEncoder不做任何处理,原样返回
public class DefaultEncoder implements Encoder {
public DefaultEncoder() {}
@Override
public String encodeText(String originalText) {
return originalText;
}
}SimpleHTMLEncoder是对HTML的特殊字符做转义
public class SimpleHTMLEncoder implements Encoder {
public SimpleHTMLEncoder() {}
@Override
public String encodeText(String originalText) {
return htmlEncode(originalText);
}
/** Encode string into HTML */
public static final String htmlEncode(String plainText) {
if (plainText == null || plainText.length() == 0) {
return "";
}
StringBuilder result = new StringBuilder(plainText.length());
for (int index = 0; index < plainText.length(); index++) {
char ch = plainText.charAt(index);
switch (ch) {
case '"':
result.append(""");
break;
case '&':
result.append("&");
break;
case '<':
result.append("<");
break;
case '>':
result.append(">");
break;
case '\'':
result.append("'");
break;
case '/':
result.append("/");
break;
default:
result.append(ch);
}
}
return result.toString();
}
}
Scorer
打分器是用来对高亮片段进行打分的。底层实现都是对高亮片段中的每个token打分,所有token的得分和就是高亮片段的总得分。
我们看下主要的接口方法
public interface Scorer {
// 在init方法中,最重要的是注册自己关注的token属性
public TokenStream init(TokenStream tokenStream) throws IOException;
// 重置一些信息来处理新的高亮片段
public void startFragment(TextFragment newFragment);
// 获取token的得分
public float getTokenScore();
// 获取当前高亮片段的得分
public float getFragmentScore();
}在lucene中,Scorer有两种不同的实现,最大区别是是否关注term之间的位置信息。
QueryTermScorer
QueryTermScorer对于所有的query都只考虑单个term的匹配情况,不考虑term之间位置距离信息。需要注意的是它没有做Query改写,所以前缀匹配,正则匹配等Query是不支持的。
这个打分器就是造成了示例中问题2的原因。示例中要查找(“lucene”,“search”)之间距离不超过1的短语匹配,因为我们例子中使用的是QueryTermScorer,它不关注位置信息,只考虑“lucene”和“search”两个term的匹配情况。
我们来看下QueryTermScorer的具体实现,先看成员变量
// 当前处理中的高亮片段
TextFragment currentTextFragment = null;
// 当前处理的高亮片段中的term集合
HashSet<String> uniqueTermsInFragment;
// 总得分
float totalScore = 0;
// term的最大权重
float maxTermWeight = 0;
// term->weightedTerm的缓存
// WeightedTerm只是简单封装了term和weight的工具类。weight也是term的得分。
// termsToFind中存储的是query中出现的所有的term和得分。
private HashMap<String, WeightedTerm> termsToFind;
// term属性
private CharTermAttribute termAtt;
currentTextFragment是一个TextFragment类型的对象引用,表示当前正在处理的高亮片段。TextFragment是 Lucene 中的一个类,它代表了文本中一个高亮显示的片段,包含片段的文本内容、起始位置和结束位置等信息。这里,currentTextFragment用于存储当前处理的文本片段,可能是通过查询匹配到的文本片段,或者是需要被高亮显示的特定文本片段。
uniqueTermsInFragment是一个HashSet<String>类型的集合,用于存储当前高亮片段中的唯一词项。这个集合用于检查和记录片段中出现的不同词项,确保每个词项只被计算一次。这通常在文本分析或信息检索任务中用于计算特定词项在文本片段中的频率或提取主题关键词。
totalScore是一个float类型的变量,表示当前高亮片段的总得分。这个得分可以基于多种因素计算,例如,它可以是片段中所有词项得分的总和。在文本分析中,总得分可以帮助你了解片段的重要性或相关性。
maxTermWeight是一个float类型的变量,表示当前高亮片段中词项的最大权重。权重通常用来衡量词项在片段中的重要性或相关性。maxTermWeight用于识别片段中最重要的词项,这个信息可以用于多种目的,例如确定片段的关键主题或提取摘要。
termsToFind是一个HashMap<String, WeightedTerm>类型的私有字段,它是一个从词项(String)到WeightedTerm对象的映射。WeightedTerm对象封装了词项文本和其对应的得分(或权重)。这个HashMap用作缓存,存储了查询中出现的所有词项及其得分。这样做可以提高效率,避免重复计算词项的得分,并在片段分析中快速访问这些数据。
termAtt是一个CharTermAttribute类型的私有字段。CharTermAttribute是 Lucene 中的一个属性类,它允许访问和操作词项的文本内容。通过termAtt,你可以提取当前Token的文本,并对其进行进一步处理或分析。这在需要操作单个词项的文本分析任务中非常有用。这些字段和对象共同合作,支持对文本片段的高效分析,包括高亮显示、得分计算、关键词提取和词项操作。
QueryTermScorer构造方法
// 使用QueryTermExtractor从query中获取所有的term。
public QueryTermScorer(Query query) {
this(QueryTermExtractor.getTerms(query));
}
// 同上
public QueryTermScorer(Query query, String fieldName) {
this(QueryTermExtractor.getTerms(query, false, fieldName));
}
// 计算term的idf作为权重
public QueryTermScorer(Query query, IndexReader reader, String fieldName) {
this(QueryTermExtractor.getIdfWeightedTerms(query, reader, fieldName));
}
// 直接传入一个已有的term集合
public QueryTermScorer(WeightedTerm[] weightedTerms) {
termsToFind = new HashMap<>();
for (int i = 0; i < weightedTerms.length; i++) {
WeightedTerm existingTerm = termsToFind.get(weightedTerms[i].term);
if ((existingTerm == null) || (existingTerm.weight < weightedTerms[i].weight)) {
// 如果是新term,或者是一个分数更高的term则更新缓存
termsToFind.put(weightedTerms[i].term, weightedTerms[i]);
maxTermWeight = Math.max(maxTermWeight, weightedTerms[i].getWeight());
}
}
}
:当前选中的代码是 Java 中的一个构造函数,它是
QueryTermScorer类的一部分。该类代表一个查询词项计分器,用于根据词项在查询中的出现情况为文本片段评分。构造函数的目的是初始化QueryTermScorer对象,为后续的评分操作做好准备。以下是代码的详细解释:
public QueryTermScorer(WeightedTerm[] weightedTerms) {...}:这是QueryTermScorer类的一个构造函数,它接收一个WeightedTerm类型的数组作为参数。WeightedTerm是一个自定义类,它代表一个带有权重的词项。在构造函数内部,首先创建一个HashMap用于存储词项及其对应的WeightedTerm对象。这个HashMap可以提高后续访问词项数据的效率。
for (int i = 0; i < weightedTerms.length; i++) {...}:这个for循环遍历传入的WeightedTerm数组。对于数组中的每一个WeightedTerm对象,它首先检查HashMap中是否已经存在该词项。如果不存在,或者新的WeightedTerm对象的权重更高,它将更新HashMap中的数据,并更新maxTermWeight变量,以记录当前看到的最高权重。
if ((existingTerm == null) || (existingTerm.weight < weightedTerms[i].weight)) {...}:这一行代码是for循环体中的核心逻辑。它检查当前WeightedTerm对象中的词项是否已经在HashMap中。如果不存在(existingTerm == null),或者当前的WeightedTerm对象具有更高的权重(existingTerm.weight < weightedTerms[i].weight),它就会执行以下操作:使用
put方法将WeightedTerm对象添加到HashMap中,键是词项文本,值是WeightedTerm对象。使用
Math.max方法更新maxTermWeight,确保它始终存储着最高的权重值。通过这个构造函数,
QueryTermScorer对象可以对传入的查询词项集合进行预处理,计算并存储每个词项的 IDF 权重,并确定集合中最高权重值。这些数据将用于后续的文本片段评分操作。评分操作可能涉及计算包含特定词项的文本片段的得分,或者根据词项权重提取重要的关键词。构造函数确保QueryTermScorer对象具有执行这些操作所需的所有数据和状态。
其他的内容我们只看两个跟打分有关的方法
// 单个token的得分
public float getTokenScore() {
String termText = termAtt.toString();
WeightedTerm queryTerm = termsToFind.get(termText);
// 如果不是query中出现的term,则直接返回得分是0。
if (queryTerm == null) {
return 0;
}
// 如果term是第一次出现,则更新总得分。可知重复出现的term对总得分没有加成
if (!uniqueTermsInFragment.contains(termText)) {
totalScore += queryTerm.getWeight();
uniqueTermsInFragment.add(termText);
}
// term的权重作为token得分
return queryTerm.getWeight();
}
// 从上面的方法可知,高亮片段的得分是每个term的权重之和,多次出现的term只取一个
public float getFragmentScore() {
return totalScore;
}
QueryScorer
QueryScorer支持所有的Query,并且对于需要考虑term组位置信息的PhraseQuery和MultiPhraseQuery都转成SpanQuery,这样可以统一处理term间的slop距离问题。只有满足slop距离要求的term组,才会被高亮处理。
因为QueryScorer涉及的内容太多了(SpanQuery,query改写,Weighter,交并集等),这边就不展开了,以QueryTermScorer为例也能清楚地了解Highlighter的工作原理。
Fragmenter
Fragmenter是对文本做分段的。主要提供了一个方法判断是否当前从TokenStream中获取到的token是否属于一个新的文本片段。
public interface Fragmenter {
// 主要是注册关注的分词属性
public void start(String originalText, TokenStream tokenStream);
// 当前TokenStream得到的token是否属于新文本段
public boolean isNewFragment();
}三个实现类
NullFragmenter
不分段
SimpleFragmenter
按照固定token个数做文本分段
// fragmentSize是文本片段的token个数
// currentNumFrags当前的文本片段个数
public boolean isNewFragment() {
boolean isNewFrag = offsetAtt.endOffset() >= (fragmentSize * currentNumFrags);
if (isNewFrag) {
currentNumFrags++;
}
return isNewFrag;
}
SimpleSpanFragmenter
SimpleSpanFragmenter在SimpleFragmenter的基础上做了一个判断,如果是满足位置条件的SpanQuery,则为了在单个高亮片段中包含满足SpanQuery的所有term,不会强制按照要求的片段大小截断(如果使用这个分片器的话,也会造成示例问题1,但是我们示例中没有使用这个分片器,那肯定还有其他原因,请继续往下看)。
高亮主逻辑
高亮的主逻辑就在Highlighter中,Highlighter中有好几个getBestFragment和getBestFragments的重载方法,最终都会走到下面这个方法
public final String[] getBestFragments(TokenStream tokenStream, String text, int maxNumFragments)
throws IOException, InvalidTokenOffsetsException {
maxNumFragments = Math.max(1, maxNumFragments);
// 获取指定的个数的高亮片段,是核心逻辑
TextFragment[] frag = getBestTextFragments(tokenStream, text, true, maxNumFragments);
// 从TextFragment中获取真正的高亮片段,前面工具类中我们说到TextFragment#toString方法就是返回真正的高亮片段
ArrayList<String> fragTexts = new ArrayList<>();
for (int i = 0; i < frag.length; i++) {
if ((frag[i] != null) && (frag[i].getScore() > 0)) {
fragTexts.add(frag[i].toString());
}
}
return fragTexts.toArray(new String[0]);
}
:当前选中的代码是 Java 中的一个方法,名为
getBestFragments。这个方法的主要目的是从文本中获取最佳的高亮片段,并以字符串数组的形式返回。下面是代码的解释:
public final String[] getBestFragments(TokenStream tokenStream, String text, int maxNumFragments) {...}:这是一个public和final修饰的方法,返回类型为String[],即字符串数组。参数列表包括一个TokenStream对象、一个文本字符串以及一个表示最大片段数量的整型参数。
maxNumFragments = Math.max(1, maxNumFragments);:这行代码确保maxNumFragments始终至少为1,即使传入的参数小于1。这可以避免在后续逻辑中出现问题。
TextFragment[] frag = getBestTextFragments(tokenStream, text, true, maxNumFragments);:调用getBestTextFragments方法,获取文本片段。这个方法的逻辑应该是处理TokenStream和文本,以确定最相关的片段。true参数可能表示某种逻辑,比如是否需要高亮显示。
ArrayList<String> fragTexts = new ArrayList<>();:创建一个ArrayList来存储满足特定条件的片段文本。随后的循环会检查每个片段是否有效(即不为null且得分大于0),如果是,就将其文本添加到这个列表中。
for (int i = 0; i < frag.length; i++) {...}:这个for循环遍历frag数组,该数组包含了文本的片段。循环内的逻辑检查每个片段是否有效,并将有效的片段文本添加到fragTexts列表中。
if ((frag[i]!= null) && (frag[i].getScore() > 0)) {...}:这个条件语句检查当前片段是否有效,即不为null,并且其得分大于0。这可能意味着这个片段被认为是重要的或者与查询相关的。
fragTexts.add(frag[i].toString());:如果片段满足上述条件,它的文本表示(通过toString方法)将被添加到fragTexts列表中。
return fragTexts.toArray(new String[0]);:循环结束后,fragTexts列表被转换为字符串数组,并作为方法的返回值。这个数组中的每个元素都代表一个有效的高亮片段的文本。这个方法可以用于搜索、信息检索或者任何需要从文本中提取相关片段的应用程序。它封装了获取和处理文本片段的逻辑,使得调用者可以轻松地获取这些片段。
getBestFragments方法的返回值可以直接作为用户界面的显示内容,或者作为进一步处理的基础数据。
Highlighter的核心方法getBestTextFragments中主逻辑可以分为四部分,在这个方法中综合使用四大组件完成高亮功能:
获取全部的片段
处理最后一个片段
对所有片段按分数排序
对首尾相连的片段merge成一个
接下来我们就详细分析这四部分的源码实现:
获取全部的片段
Highlighter会获取所有的片段做备选,不管是否包含关键字。我们先看下获取高亮片段的一个整体流程:
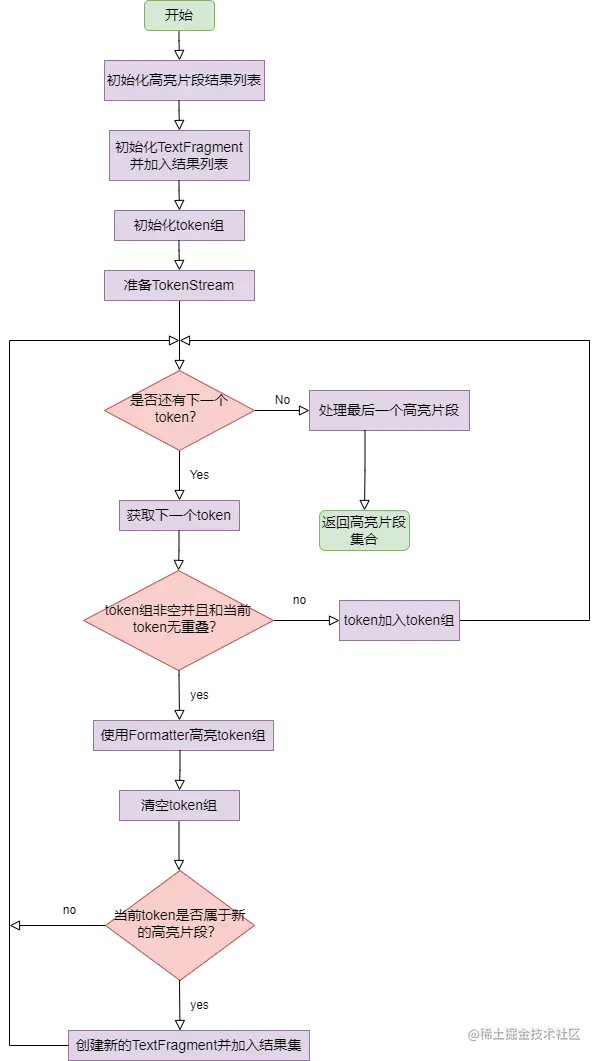
源码对应上面的流程图看,逻辑还是比较清晰的
public final TextFragment[] getBestTextFragments(
TokenStream tokenStream, String text, boolean mergeContiguousFragments, int maxNumFragments)
throws IOException, InvalidTokenOffsetsException {
// 初始化结果集
ArrayList<TextFragment> docFrags = new ArrayList<>();
// 完整的文本,对匹配的term做了高亮处理
StringBuilder newText = new StringBuilder();
CharTermAttribute termAtt = tokenStream.addAttribute(CharTermAttribute.class);
OffsetAttribute offsetAtt = tokenStream.addAttribute(OffsetAttribute.class);
// 初始化当前处理的TextFragment
TextFragment currentFrag = new TextFragment(newText, newText.length(), docFrags.size());
if (fragmentScorer instanceof QueryScorer) {
((QueryScorer) fragmentScorer).setMaxDocCharsToAnalyze(maxDocCharsToAnalyze);
}
TokenStream newStream = fragmentScorer.init(tokenStream);
if (newStream != null) {
tokenStream = newStream;
}
fragmentScorer.startFragment(currentFrag);
// 把当前的片段加入结果集
docFrags.add(currentFrag);
// 高亮片段的堆,用来按得分排序的,如果分数相等,分片编号小的在堆顶。注意是有限的。
FragmentQueue fragQueue = new FragmentQueue(maxNumFragments);
try {
String tokenText;
int startOffset;
int endOffset;
// 上一次文本片段结束的位置
int lastEndOffset = 0;
textFragmenter.start(text, tokenStream);
// 初始化token组
TokenGroup tokenGroup = new TokenGroup(tokenStream);
tokenStream.reset();
// 遍历所有的token
for (boolean next = tokenStream.incrementToken();
next && (offsetAtt.startOffset() < maxDocCharsToAnalyze);
next = tokenStream.incrementToken()) {
if ((offsetAtt.endOffset() > text.length()) || (offsetAtt.startOffset() > text.length())) {
throw new InvalidTokenOffsetsException(
"Token "
+ termAtt.toString()
+ " exceeds length of provided text sized "
+ text.length());
}
// 如果当前token组非空并且当前处理的token和token组没有重叠
if ((tokenGroup.getNumTokens() > 0) && (tokenGroup.isDistinct())) {
// 获取当前token组中的内容进行高亮
startOffset = tokenGroup.getStartOffset();
endOffset = tokenGroup.getEndOffset();
tokenText = text.substring(startOffset, endOffset);
// 这一步就会对匹配的关键字做高亮
String markedUpText = formatter.highlightTerm(encoder.encodeText(tokenText), tokenGroup);
// 如果token组合上一次片段的结尾中间还有内容,则把这部分加入完整的文本中
if (startOffset > lastEndOffset)
newText.append(encoder.encodeText(text.substring(lastEndOffset, startOffset)));
// 加入高亮之后的内容
newText.append(markedUpText);
// 更新上一次文本片段结束的位置
lastEndOffset = Math.max(endOffset, lastEndOffset);
// 清空token组
tokenGroup.clear();
// 如果当前token属于新的片段。
// 需要为当前片段做一些收尾工作,比如计算总得分,记录在当前片段在文本中的结束位置
if (textFragmenter.isNewFragment()) {
// 计算当前片段的得分
currentFrag.setScore(fragmentScorer.getFragmentScore());
// 记录在当前片段在文本中的结束位置
currentFrag.textEndPos = newText.length();
// 创建一个新的片段,准备处理后面的token
currentFrag = new TextFragment(newText, newText.length(), docFrags.size());
fragmentScorer.startFragment(currentFrag);
// 把当前片段加入结果集
docFrags.add(currentFrag);
}
}
// 当前的token加入token组
tokenGroup.addToken(fragmentScorer.getTokenScore());
}
。。。(处理最后一个片段)
。。。(对所有片段按分数排序)
。。。(对首尾相连的片段merge成一个)
} finally {
if (tokenStream != null) {
try {
tokenStream.end();
tokenStream.close();
} catch (
@SuppressWarnings("unused")
Exception e) {
}
}
}
}
:这段代码是在遍历文本中的 token 时,对每个 token 进行处理,并在处理过程中动态地维护文本片段信息。下面是对代码的详细解释:
for (boolean next = tokenStream.incrementToken(); next && (offsetAtt.startOffset() < maxDocCharsToAnalyze); next = tokenStream.incrementToken()) {...}:这是一个循环,用于遍历TokenStream中的每个Token。tokenStream.incrementToken()用于移动到下一个Token,并返回一个布尔值表示是否有下一个Token。next变量用于存储这个布尔值,它在每次循环开始时被更新。offsetAtt.startOffset() < maxDocCharsToAnalyze这个条件用于确保Token的起始偏移量不超过文档的最大字符数,以防止处理超出文档范围的Token。
if ((offsetAtt.endOffset() > text.length()) || (offsetAtt.startOffset() > text.length())) {...}:这是一个错误检查,用于防止Token的偏移量超出文本的长度。如果发生这种情况,将抛出一个InvalidTokenOffsetsException异常,指出Token超出了text的长度。
if ((tokenGroup.getNumTokens() > 0) && (tokenGroup.isDistinct())) {...}:这个条件语句检查当前的TokenGroup是否为空,以及当前的Token是否与组内已有的Token重叠。tokenGroup.getNumTokens() > 0表示组内有Token。tokenGroup.isDistinct()调用了TokenGroup类中的isDistinct方法,这个方法可能用于检查当前Token的起始偏移量是否大于或等于组内最后一个Token的结束偏移量。如果这两个条件都满足,代码将进入到下一部分。
startOffset = tokenGroup.getStartOffset();:tokenGroup.getStartOffset()可能是TokenGroup类中的一个方法,它返回组内第一个Token的起始偏移量。这个值被存储在startOffset变量中。
endOffset = tokenGroup.getEndOffset();:tokenGroup.getEndOffset()可能是TokenGroup类中的一个方法,它返回组内最后一个Token的结束偏移量。这个值被存储在endOffset变量中。
tokenText = text.substring(startOffset, endOffset);:使用上一步骤中获得的起始和结束偏移量,使用substring方法从原始文本text中提取实际的Token文本。
markedUpText = formatter.highlightTerm(encoder.encodeText(tokenText), tokenGroup);:调用formatter对象的highlightTerm方法对提取的tokenText进行高亮处理。encoder.encodeText可能是对tokenText进行编码或转换,以确保formatter能够正确处理它。tokenGroup作为参数传递给highlightTerm方法,可能是因为它包含了Token的信息,例如Token在文档中的位置或者其他属性,这些信息可能被formatter用于确定如何高亮显示。
newText.append(markedUpText);:将高亮处理后的文本markedUpText添加到newText字符串构建器中。newText似乎是用来构建最终高亮显示的文本。
tokenGroup.clear();:清空tokenGroup,准备处理新的Token。这表明tokenGroup是一个可变对象,用于存储当前正在处理的Token。
if (textFragmenter.isNewFragment()) {...}:textFragmenter.isNewFragment()调用了TextFragmenter类中的一个方法,这个方法用于判断当前的Token是否属于一个新的片段。如果是,需要对当前片段做一些收尾工作,比如计算总得分,记录在当前片段在文本中的结束位置,并创建一个新的片段,准备处理后面的token 。
currentFrag.setScore(fragmentScorer.getFragmentScore());:如果Token属于一个新的片段,使用fragmentScorer的getFragmentScore方法来设置当前片段的得分。这表明fragmentScorer类有一个方法可以基于tokenGroup中的信息来计算片段的得分。
currentFrag.textEndPos = newText.length();:更新当前片段在文本中的结束位置。newText.length()将提供新添加的高亮文本之后的文本长度,这可以用作当前片段的结束位置。
currentFrag = new TextFragment(newText, newText.length(), docFrags.size());:创建一个新的TextFragment对象,它代表了文本中的一个新片段。这个新对象使用更新后的newText和它的长度,以及在docFrags集合中的索引(通过docFrags.size())。
fragmentScorer.startFragment(currentFrag);:使用fragmentScorer来启动或识别这个新片段。这可能涉及到设置片段的起始位置或任何其他需要的初始化。
docFrags.add(currentFrag);:将新的TextFragment对象添加到docFrags集合中。这可能是用于跟踪文档中所有高亮显示的片段。这种设计允许程序动态地识别文本中的片段,根据需要对每个片段进行高亮显示,并维护文档中所有片段的集合。这对于实现搜索结果高亮显示或其他需要文本片段分析的应用程序是有用的。
处理最后一个片段
最后一个token处理完成,还需要为当前处理中的最后一个片段做收尾工作
public final TextFragment[] getBestTextFragments(
TokenStream tokenStream, String text, boolean mergeContiguousFragments, int maxNumFragments)
throws IOException, InvalidTokenOffsetsException {
。。。(获取所有的高亮片段)
// 处理最后一个片段,最后一个token可能不是刚好满足一个片段的大小
currentFrag.setScore(fragmentScorer.getFragmentScore());
// 如果token组非空,则把token组进行高亮,再加入完整的文本序列中,这部分逻辑和获取所有的片段中的一致
if (tokenGroup.getNumTokens() > 0) {
startOffset = tokenGroup.getStartOffset();
endOffset = tokenGroup.getEndOffset();
tokenText = text.substring(startOffset, endOffset);
String markedUpText = formatter.highlightTerm(encoder.encodeText(tokenText), tokenGroup);
if (startOffset > lastEndOffset)
newText.append(encoder.encodeText(text.substring(lastEndOffset, startOffset)));
newText.append(markedUpText);
lastEndOffset = Math.max(lastEndOffset, endOffset);
}
// 如果还存在输入文本的内容,则把剩余部分也加入完整的文本序列中
if (lastEndOffset < text.length() && text.length() <= maxDocCharsToAnalyze) {
newText.append(encoder.encodeText(text.substring(lastEndOffset)));
}
// 标记最后一个片段的结束位置
currentFrag.textEndPos = newText.length();
。。。(对所有片段按分数排序)
。。。(对首尾相连的片段merge成一个)
return frag;
} finally {
if (tokenStream != null) {
try {
tokenStream.end();
tokenStream.close();
} catch (
@SuppressWarnings("unused")
Exception e) {
}
}
}
}
getBestTextFragments方法的目的是从一个文本中提取出最佳的文本片段,并进行高亮显示。这些片段通常是基于某种查询或者文本分析的结果。以下是代码解释:
public final TextFragment[] getBestTextFragments(TokenStream tokenStream, String text, boolean mergeContiguousFragments, int maxNumFragments) throws IOException, InvalidTokenOffsetsException {...}:这个方法的参数列表包括一个TokenStream对象、一个原始文本字符串、一个布尔值表示是否合并连续片段,以及一个整数表示最大片段数量。方法用throws关键字声明了它可以抛出IOException和InvalidTokenOffsetsException异常。
// 处理最后一个片段,最后一个token可能不是刚好满足一个片段的大小:这行注释解释了代码将会对获取到的高亮片段进行处理,确保最后一个片段的大小是完整的。在文本分析中,最后一个Token可能不完整,因此需要特殊处理来保证片段的连贯性。
currentFrag.setScore(fragmentScorer.getFragmentScore());:这行代码调用了fragmentScorer对象的getFragmentScore方法,并将返回值设置为currentFrag对象的score属性。fragmentScorer通常是一个用于计算文本片段得分的对象,这个得分用来衡量片段的重要性或者与查询的相关性。
// 如果token组非空,则把token组进行高亮,再加入完整的文本序列中,这部分逻辑和获取所有的片段中的一致:这行注释解释了接下来的代码块逻辑。如果tokenGroup中存在Token,将提取tokenGroup中的文本片段,进行高亮显示,然后将高亮显示后的文本添加到newText对象中。这个逻辑和获取所有片段的逻辑是一致的,确保了一致性和完整性。
if (tokenGroup.getNumTokens() > 0) {...}:这行代码判断tokenGroup中是否存在Token。如果存在,将执行以下步骤:startOffset = tokenGroup.getStartOffset(); endOffset = tokenGroup.getEndOffset(); tokenText = text.substring(startOffset, endOffset); String markedUpText = formatter.highlightTerm(encoder.encodeText(tokenText), tokenGroup); if (startOffset > lastEndOffset) newText.append(encoder.encodeText(text.substring(lastEndOffset, startOffset))); newText.append(markedUpText); lastEndOffset = Math.max(lastEndOffset, endOffset);
// 如果还存在输入文本的内容,则把剩余部分也加入完整的文本序列中:这行注释表明,如果在处理完所有Token后,还有未处理的原始文本部分,这些部分也将被添加到newText对象中。这确保了newText包含了原始文本的所有内容,只是其中的某些部分可能被高亮显示了。
if (lastEndOffset < text.length() && text.length() <= maxDocCharsToAnalyze) {...}:这行代码通过判断lastEndOffset是否小于text.length(),来确定是否还有未处理的文本内容。同时,text.length() <= maxDocCharsToAnalyze这个条件确保了处理的文本长度没有超过文档的最大字符数限制。
newText.append(encoder.encodeText(text.substring(lastEndOffset)));:如果存在剩余文本,它将会被编码后添加到newText中。
// 标记最后一个片段的结束位置:这行注释说明接下来的代码是用来标记最后一个片段的结束位置。
currentFrag.textEndPos = newText.length();:通过newText.length()获取当前newText对象的长度,并将其赋值给currentFrag的textEndPos属性,这个属性用于标记当前片段在文本中的结束位置。
// 对所有片段按分数排序:这行注释提示了代码的下一步逻辑,即对所有frag对象进行排序。排序可能是基于score属性,以确保最重要或最相关的片段排在前面。
// 对首尾相连的片段merge成一个:这行注释提示了另一个可能的逻辑,即对排序后的frag对象进行进一步处理,将那些首尾相连的片段合并为一个。这样做可以减少片段的数量,提高显示效率,同时也可以使得显示结果更加简洁明了。
return frag;:最后,排序和合并后的frag对象将被作为方法的返回值,返回给调用者。这些frag对象代表了文本中最重要和最相关的片段,可以被用于显示或进一步处理。
} finally {...}:这个finally块确保了TokenStream资源在使用后被正确地释放。即使方法中发生了异常,tokenStream.end();和tokenStream.close();语句也会被执行,防止资源泄漏。总的来说,
getBestTextFragments方法是一个复杂但有组织的文本处理方法,它不仅考虑了文本的片段提取,还涉及到这些片段的高亮显示、排序和合并。finally块中的资源管理确保了方法的健壮性,避免了潜在的资源泄漏问题。
对所有片段按分数排序
最终的片段是按照分数排序,只保留了maxNumFragments个片段,注意其中不一定都是包含关键字的
public final TextFragment[] getBestTextFragments(
TokenStream tokenStream, String text, boolean mergeContiguousFragments, int maxNumFragments)
throws IOException, InvalidTokenOffsetsException {
。。。(获取所有的片段)
。。。(处理最后一个片段)
// 把片段插入最大堆中(堆顶的片段分数最高,如果分数相等,分片编号小的在堆顶)
for (Iterator<TextFragment> i = docFrags.iterator(); i.hasNext(); ) {
currentFrag = i.next();
fragQueue.insertWithOverflow(currentFrag);
}
// 从堆中依次取出片段,在数组中的顺序就是按照得分从高到低
TextFragment[] frag = new TextFragment[fragQueue.size()];
for (int i = frag.length - 1; i >= 0; i--) {
frag[i] = fragQueue.pop();
}
。。。(对首尾相连的片段merge成一个)
} finally {
if (tokenStream != null) {
try {
tokenStream.end();
tokenStream.close();
} catch (
@SuppressWarnings("unused")
Exception e) {
}
}
}
}
:当前选中的代码是 Java 中的一个方法,名为
getBestTextFragments。这个方法的目的是从文本中提取最相关的片段,并将这些片段作为TextFragment对象的数组返回。以下是代码的详细解释:
public final TextFragment[] getBestTextFragments(TokenStream tokenStream, String text, boolean mergeContiguousFragments, int maxNumFragments) throws IOException, InvalidTokenOffsetsException {...}:这是一个公共的最终方法,它不允许在子类中被覆盖,并且返回一个TextFragment对象的数组。这个方法接收四个参数:一个TokenStream对象,它用于访问文本中的标记;一个String对象,表示要分析的文本;一个布尔值,表示是否合并连续的片段;以及一个整数,表示要返回的最大片段数。这个方法可能会抛出IOException和InvalidTokenOffsetsException两种异常。
// 把片段插入最大堆中(堆顶的片段分数最高,如果分数相等,分片编号小的在堆顶):这行注释解释了接下来代码块的目的。代码使用一个循环遍历docFrags集合中的每个TextFragment。在循环内部,使用fragQueue.insertWithOverflow(currentFrag);将当前TextFragment对象插入到一个PriorityQueue中。fragQueue被描述为一个最大堆,意味着堆顶的元素具有最高的得分。如果两个片段得分相同,编号较小的片段将被放置在堆顶。这种设计确保了最高得分的片段总是在堆顶,并且在得分相同时,最先出现的片段在数组中排名更高。
// 从堆中依次取出片段,在数组中的顺序就是按照得分从高到低:这行注释描述了如何从PriorityQueue中提取TextFragment对象。代码创建一个新的TextFragment数组frag,其大小与fragQueue相同。然后,它使用一个循环,从数组的末尾开始,使用fragQueue.pop();从堆中移除堆顶的元素,并将其放入frag数组中。由于PriorityQueue自动维护元素的顺序,最先弹出的元素将是得分最高的。
// 对首尾相连的片段merge成一个:这行注释表明在返回片段之前,代码可能会对它们进行额外的处理。这可能意味着将那些在文本中物理上相邻的片段合并成一个单一的逻辑片段。这种合并通常发生在连续的片段之间没有逻辑分隔符时,或者当合并它们可以提高可读性或减少冗余时。实现这种合并的方式可以是通过维护片段的开始和结束位置信息,然后合并那些位置连续的片段。具体实现将取决于TextFragment类中可用的属性和方法。
} finally {...}:这个finally块确保即使发生异常,TokenStream也会被正确地清理。如果tokenStream不为空,finally块将尝试执行end()和close()方法来终止和关闭TokenStream。这样可以防止资源泄漏,并确保在getBestTextFragments方法执行完毕后,所有相关资源都被妥善处理。
对首尾相连的片段merge成一个
如果最后结果中的片段集合有首尾相接的,则merge成一个片段。这个逻辑也是造成示例问题1的原因之一。
public final TextFragment[] getBestTextFragments(
TokenStream tokenStream, String text, boolean mergeContiguousFragments, int maxNumFragments)
throws IOException, InvalidTokenOffsetsException {
。。。(获取所有的片段)
。。。(处理最后一个片段)
。。。(对所有片段按分数排序)
// 如果最后结果中的片段集合有首尾相接的,则merge成一个片段。
// 这个逻辑就是造成示例问题1的原因
if (mergeContiguousFragments) {
// 具体实现merge的逻辑可以自己看,虽然比较长,但是比较简单,就是暴力搜索看看是否首尾相接。
mergeContiguousFragments(frag);
ArrayList<TextFragment> fragTexts = new ArrayList<>();
for (int i = 0; i < frag.length; i++) {
if ((frag[i] != null) && (frag[i].getScore() > 0)) {
fragTexts.add(frag[i]);
}
}
frag = fragTexts.toArray(new TextFragment[0]);
}
return frag;
} finally {
if (tokenStream != null) {
try {
tokenStream.end();
tokenStream.close();
} catch (
@SuppressWarnings("unused")
Exception e) {
}
}
}
}
getBestTextFragments方法的目的是从文本中提取最相关的片段,并将这些片段作为TextFragment对象的数组返回。这个方法接收四个参数:一个TokenStream对象,用于访问文本中的标记;一个String对象,表示要分析的文本;一个布尔值,表示是否合并连续的片段;以及一个整数,表示要返回的最大片段数。这个方法可能会抛出IOException和InvalidTokenOffsetsException两种异常。方法的实现首先创建一个
PriorityQueue对象fragQueue,并初始化一个与docFrags集合大小相同的TextFragment数组frag。然后,通过循环将docFrags集合中的每个TextFragment对象插入到fragQueue中。`fragQueue` 是一个最大堆,意味着堆顶的元素具有最高的得分。如果两个片段得分相同,编号较小的片段将被放置在堆顶。接着,方法创建一个新的
TextFragment数组frag,其大小与fragQueue相同。然后,使用一个循环从数组的末尾开始,从fragQueue中移除堆顶的元素,并将其放入frag数组中。由于PriorityQueue自动维护元素的顺序,最先弹出的元素将是得分最高的。随后,方法进行合并连续片段的操作。如果
mergeContiguousFragments参数为true,则调用mergeContiguousFragments方法来合并frag数组中的连续片段。合并的具体逻辑是通过暴力搜索,检查每个片段的结尾位置和下一个片段的开始位置是否相接。如果相接,则合并这两个片段成为一个新的TextFragment对象。合并后的片段将被添加到一个新的ArrayList对象fragTexts中。然后,方法对
fragTexts集合中的TextFragment对象进行遍历。如果集合中的某个对象不为null,并且其得分大于0,则将其添加到fragTexts集合中。这一步骤确保了合并操作后,只有有效的片段被保留下来。最后,方法将
fragTexts集合转换为一个TextFragment数组,并将这个数组作为方法的返回值。返回的数组代表了经过合并操作后的最相关文本片段,可以根据需要进行进一步处理或展示。在方法的
finally块中,确保了TokenStream对象在使用后被正确地清理。如果tokenStream不为空,`finally` 块将尝试执行end()和close()方法来终止和关闭TokenStream。这样可以防止资源泄漏,并确保在getBestTextFragments方法执行完毕后,所有相关资源都被妥善处理。
merge逻辑处理之后的片段结果集作为最终的高亮片段集合返回。
总结
经过上面的分析,我们也了解了Highlighter工作原理,从中也可以发现Highlighter虽然可以满足高亮的需求,但是仍然存在问题:
Highlighter不适用于大文档,因为它是通过走一遍分词器,遍历token寻找匹配关键字,效率比较低。
Highlighter最后会对首尾相连的片段进行合并,而拼接的可能是不包含关键字的片段,导致可能整体看起来相关性被稀释,如我们示例中的结果1。
对于Highlighter存在的这两个问题该怎么优化呢?我们下一篇见。