前提
在Lucene 9.1.0中,向量的近邻检索算法只提供了HNSW,因此本文介绍的Lucene向量数据的读写就是介绍Lucene中HNSW相关数据文件的读写。
在学习Lucene中HNSW相关数据文件结构的持久化和解析之前,建议先阅读下 历史文章《lucene源码系列:HNSW实现》,以便了解HNSW的构建流程以及最终HNSW的数据结构包含哪些信息。
本文中向量数据文件的格式以及源码解析都是基于Lucene 9.1.0版本。
概述
Lucene 中每个segment中向量相关的数据文件一共有三个:
vec扩展名:向量数据文件
vex扩展名:向量索引文件(存储邻居数据)
vem扩展名:向量元信息文件(用来定位读取vec和vex)
通过这三个文件可以恢复每个向量字段的HNSW图结构,从而支持在向量字段上的近邻检索。至于每个文件的结构,如何生成以及如何读取解析的,让我们接下来逐一分析。
在 Lucene 中,每个 segment 包含多个文件,其中与向量相关的数据文件主要有三个:
vec 扩展名:向量数据文件
这个文件存储了实际的向量数据。每个向量由一组浮点数表示,这些浮点数对应于向量的各个维度。
向量数据文件通常以二进制格式存储,以提高读写效率。
vex 扩展名:向量索引文件(存储邻居数据)
这个文件存储了向量的索引信息,特别是用于近似最近邻(ANN)搜索的邻居数据。
vex 文件通常包含每个向量的 ID 和其对应的邻居向量的 ID 及距离信息。这些信息用于加速搜索过程,减少需要比较的向量数量。
vem 扩展名:向量元信息文件(用来定位读取 vec 和 vex)
这个文件存储了向量的元信息,包括向量的数量、每个向量的维度、vec 和 vex 文件的偏移量等。
vem 文件用于帮助定位和读取 vec 和 vex 文件中的具体数据,确保数据的一致性和完整性。
这些文件共同构成了 Lucene 中向量数据的存储结构,使得向量数据可以被高效地存储、索引和查询。特别是在大规模数据集和实时搜索场景中,这种结构能够显著提高性能和可扩展性。
文件结构
我们先从全局看下每个文件的具体结构,然后再看它们是如何生成和读取解析的。
vec文件结构
向量数据的文件结构是三个文件中最简单,它包含所有字段的向量数据,如下图所示:
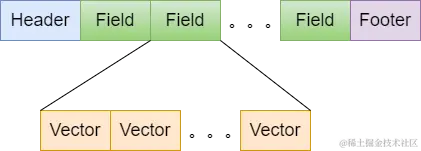
Header
文件头部信息,主要是包括:
•文件头魔数(同一lucene版本所有文件相同)
•该文件使用的codec名称:Lucene91HnswVectorsFormatData
•codec版本:0
•segment id: 段唯一标识符,标识这个文件属于哪个段的
•segment后缀名:Lucene91HnswVectorsFormat_0
Field
每一个向量字段就有一个Field,同一个字段的向量数据都存在一起。文档中的所有向量字段依次存储。
Vector
真正序列化的向量数据
Footer
文件尾,主要包括:
文件尾魔数(同一个lucene版本所有文件一样)
0
校验码
vex文件结构
向量索引文件中包含了所有字段的构建出来的HNSW的邻居信息,具体结构如下图所示:
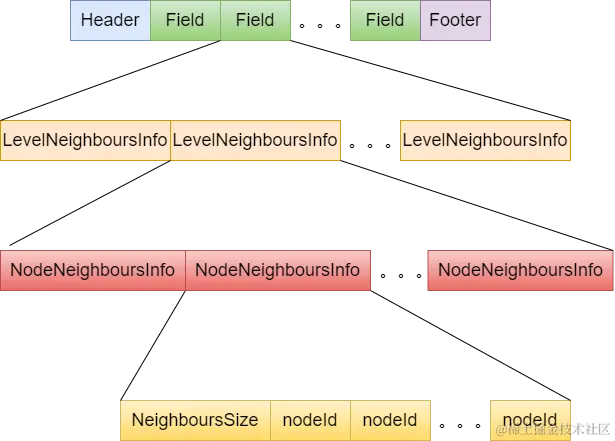
Header
文件头部信息,主要是包括:
•文件头魔数(同一lucene版本所有文件相同)
•该文件使用的codec名称:Lucene91HnswVectorsFormatIndex
•codec版本:0
•segment id: 段唯一标识符,标识这个文件属于哪个段的
•segment后缀名:Lucene91HnswVectorsFormat_0
Field
每一个向量字段就有一个Field,同一个字段的邻居数据都存在一起。文档中的所有向量字段依次存储。
LevelNeighboursInfo
当前字段HNSW结构中每一层的所有节点的邻居信息
NodeNeighboursInfo
节点的所有的邻居信息
•NeighboursSize:真实邻居的个数
•nodeId:邻居的节点编号,个数不足maxConn的,补0。方便读取文件时直接计算offset读取指定节点的邻居信息(详见后面文件读取的介绍)。
Footer
文件尾,主要包括
•文件尾魔数(同一个lucene版本所有文件一样)
•0
•校验码
vem文件结构
向量元信息文件中保存了读取指定位置的vec和vex所需要的信息,也是构建HNSW的关键,因此它的结构是三个文件中最复杂的,具体结构如下图所示:
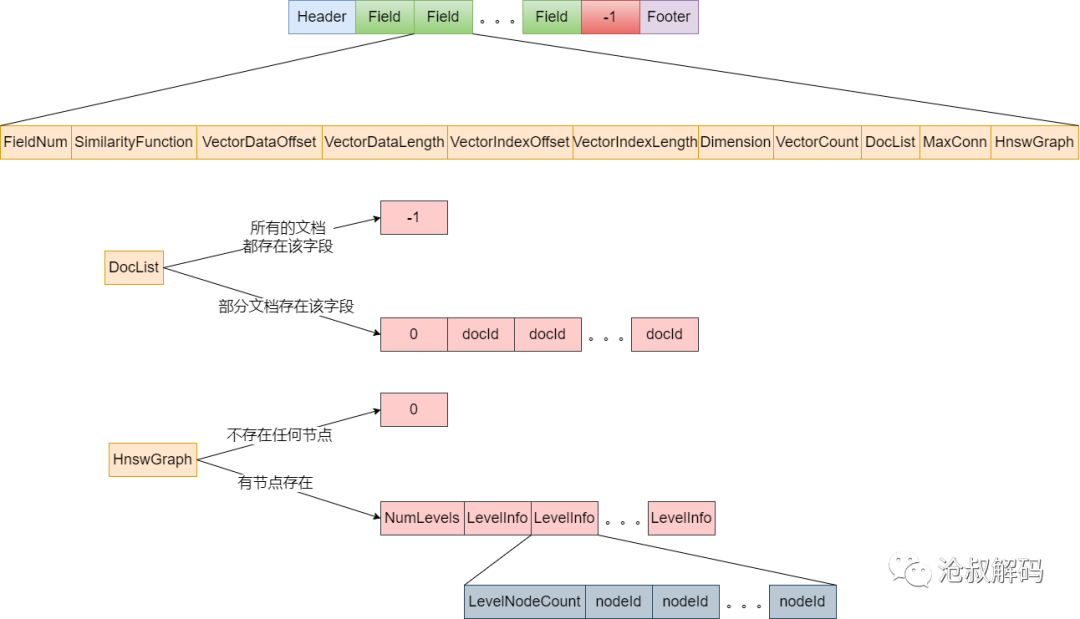
Header
文件头部信息,主要是包括:
•文件头魔数(同一lucene版本所有文件相同)
•该文件使用的codec名称:Lucene91HnswVectorsFormatMeta
•codec版本:0
•segment id: 段唯一标识符,标识这个文件属于哪个段的
•segment后缀名:Lucene91HnswVectorsFormat_0
Field
每一个向量字段就有一个Field,同一个字段的元信息数据都存在一起。文档中的所有向量字段依次存储。
FieldNum
字段的编号,lucene内部每处理一个字段都会为它生成一个字段编号
SimilarityFunction
距离的度量函数类型
VectorDataOffset
向量数据文件中的该字段的起始offset
VectorDataLength
向量数据文件中的该字段的数据总长度
VectorIndexOffset
向量索引文件中该字段的起始offset
VectorIndexLength
向量索引文件中的该字段的数据总长度
Dimension
该字段的向量的维度
VectorCount
segment中该字段的向量总数,也是包含该向量字段的文档个数
DocList
包含该字段的文档列表。如果没有文档包含该字段,则写-1。否则先写0,再写入所有的docid。
MaxConn
每个节点最多的邻居个数
HnswGraph
HNSW的图结构信息。如果图中不存在任何节点,则写0。
•NumLevels:层数
•LevelInfo:每层的节点信息,
•LevelNodeCount:节点个数
•NodeId:所有节点的id
-1
字段结束的标记。元信息中没有记录有多少个向量字段,因此写一个标记作为遍历停止的判断条件。
Footer
文件尾,主要包括
•文件尾魔数(同一个lucene版本所有文件一样)
•0
•校验码
文件生成
了解了上一节的文件结构之后,再来看文件生成的代码逻辑其实非常简单,在跟源码的过程中注意对照文件结构图来看。
Lucene91HnswVectorsWriter
向量的三个文件生成逻辑都在Lucene91HnswVectorsWriter类中,在Lucene91HnswVectorsWriter中对这三个文件的名字生成,写文件头Header和文件尾注脚逻辑是一样的,这部分相同逻辑我们先看下。
先看下Lucene91HnswVectorsWriter中的成员变量,跟文件相关的是三个输出流成员变量,分别对应了这三个文件:
// 持久化的相关文件的输出流
// meta:向量元信息文件输出流
// vectorData: 向量数据文件输出流
// vectorIndex: 向量索引文件输出流(存储邻居信息)
private final IndexOutput meta, vectorData, vectorIndex;在Lucene91HnswVectorsWriter的构造函数中会初始化这三个文件的文件名和输出流,同时为三个文件加上文件头部Header:
Lucene91HnswVectorsWriter(SegmentWriteState state, int maxConn, int beamWidth)
throws IOException {
this.maxConn = maxConn;
this.beamWidth = beamWidth;
assert state.fieldInfos.hasVectorValues();
segmentWriteState = state;
// 文件名是 _段编号_段后缀名.文件扩展名
// 段后缀名三个文件是统一的:Lucene91HnswVectorsFormat_0
String metaFileName =
IndexFileNames.segmentFileName(
state.segmentInfo.name, state.segmentSuffix, Lucene91HnswVectorsFormat.META_EXTENSION);
String vectorDataFileName =
IndexFileNames.segmentFileName(
state.segmentInfo.name,
state.segmentSuffix,
Lucene91HnswVectorsFormat.VECTOR_DATA_EXTENSION);
String indexDataFileName =
IndexFileNames.segmentFileName(
state.segmentInfo.name,
state.segmentSuffix,
Lucene91HnswVectorsFormat.VECTOR_INDEX_EXTENSION);
boolean success = false;
try {
// 初始化话三个文件的输出流
meta = state.directory.createOutput(metaFileName, state.context);
vectorData = state.directory.createOutput(vectorDataFileName, state.context);
vectorIndex = state.directory.createOutput(indexDataFileName, state.context);
// 分别写入文件头
// 文件头信息有:
// 1.文件头魔数(同一lucene版本所有文件相同)
// 2.该文件使用的codec名称:Lucene91HnswVectorsFormatData
// 3.codec版本:0
// 4.segment id: 段唯一标识符,标识这个文件属于哪个段的
// 5.segment后缀名:Lucene91HnswVectorsFormat_0
CodecUtil.writeIndexHeader(
meta,
Lucene91HnswVectorsFormat.META_CODEC_NAME,
Lucene91HnswVectorsFormat.VERSION_CURRENT,
state.segmentInfo.getId(),
state.segmentSuffix);
CodecUtil.writeIndexHeader(
vectorData,
Lucene91HnswVectorsFormat.VECTOR_DATA_CODEC_NAME,
Lucene91HnswVectorsFormat.VERSION_CURRENT,
state.segmentInfo.getId(),
state.segmentSuffix);
CodecUtil.writeIndexHeader(
vectorIndex,
Lucene91HnswVectorsFormat.VECTOR_INDEX_CODEC_NAME,
Lucene91HnswVectorsFormat.VERSION_CURRENT,
state.segmentInfo.getId(),
state.segmentSuffix);
maxDoc = state.segmentInfo.maxDoc();
success = true;
} finally {
if (success == false) {
IOUtils.closeWhileHandlingException(this);
}
}
}在文件数据写入完成之后,还需要对着三个文件写个文件尾(主要是校验码),向量元信息文件比较特殊,会写个-1表示字段信息的结束:
public void finish() throws IOException {
if (finished) {
throw new IllegalStateException("already finished");
}
finished = true;
if (meta != null) {
// -1是表示向量元信息的主内容已经结束。
// 多个向量字段的向量元信息是写在一起的,因为没有单独记录有多少个向量字段,所以用-1作为字段结束标记
meta.writeInt(-1);
// 写文件注脚,注脚内容:
// 1.文件尾魔数(同一个lucene版本所有文件一样)
// 2.0
// 3.校验码
CodecUtil.writeFooter(meta);
}
if (vectorData != null) {
CodecUtil.writeFooter(vectorData);
CodecUtil.writeFooter(vectorIndex);
}
}介绍完三个文件的共同逻辑之后,接下来分别详细介绍这三个文件的生成。
vec文件生成
向量数据文件是最简单的一个文件了,保存了所有字段的向量数据,每个字段的向量数据存储在一起。
向量数据的写入逻辑在org.apache.lucene.codecs.lucene91.Lucene91HnswVectorsWriter#writeField中,先把向量数据写临时文件,以防HNSW构建失败导致数据丢失,然后把临时文件中的数据拷贝到向量数据文件中,逻辑非常简单,需要注意的是每个字段都会生成该字段向量数据在向量文件中的起始位置vectorDataOffset和数据总长度vectorDataLength,会把这两个信息写入向量元信息文件,这样读取的时候就可以根据向量元信息中的这两个字段获取对应字段的向量数据。我们来看下实现:
public void writeField(FieldInfo fieldInfo, KnnVectorsReader knnVectorsReader)
throws IOException {
// 计算当前字段中所有向量数据在向量数据文件的起始位置,该信息会写入元信息文件
long vectorDataOffset = vectorData.alignFilePointer(Float.BYTES);
VectorValues vectors = knnVectorsReader.getVectorValues(fieldInfo.name);
IndexOutput tempVectorData =
segmentWriteState.directory.createTempOutput(
vectorData.getName(), "temp", segmentWriteState.context);
IndexInput vectorDataInput = null;
boolean success = false;
try {
// 向量的数据先存临时文件,构建HNSW失败不会删除临时文件,构建成功则会删除临时文件
DocsWithFieldSet docsWithField = writeVectorData(tempVectorData, vectors);
CodecUtil.writeFooter(tempVectorData);
IOUtils.close(tempVectorData);
// 从临时文件中读取向量数据
vectorDataInput =
segmentWriteState.directory.openInput(
tempVectorData.getName(), segmentWriteState.context);
// 重点来了,向量的数据都拷贝到最后落盘文件的输出流中
vectorData.copyBytes(vectorDataInput, vectorDataInput.length() - CodecUtil.footerLength());
CodecUtil.retrieveChecksum(vectorDataInput);
// 计算当前字段所有向量数据的总长度,该信息会写入元信息文件
long vectorDataLength = vectorData.getFilePointer() - vectorDataOffset;
。。。(省略元信息文件和索引文件持久化逻辑,后面单独讨论)
} finally {
。。。(省略资源关闭)
}
}
vex文件生成
虽然官方叫vex文件是向量索引文件,目前的版本我觉得并不合适,因为这个文档是单独存储HNSW所有层的所有节点的邻居信息。而对于向量数据文件和邻居数据文件的读取,其实用的还是向量元信息文件中的信息来作为索引。
向量索引文件的写入是在构建HNSW之后,和向量数据文件一样,也会记录每个字段在向量索引文件起始位置和数据长度,最终写入向量元信息文件中:
@Override
public void writeField(FieldInfo fieldInfo, KnnVectorsReader knnVectorsReader)
throws IOException {
。。。(忽略和索引文件落盘无关逻辑)
try {
。。。(忽略和索引文件落盘无关逻辑)
// 计算当前处理的字段的索引文件信息的起始位置,该信息会写入元信息文件
long vectorIndexOffset = vectorIndex.getFilePointer();
//
Lucene91HnswVectorsReader.OffHeapVectorValues offHeapVectors =
new Lucene91HnswVectorsReader.OffHeapVectorValues(
vectors.dimension(), docsWithField.cardinality(), null, vectorDataInput);
OnHeapHnswGraph graph =
offHeapVectors.size() == 0
? null
// 索引信息存储的是邻居信息,所以必须先构建HNSW
: writeGraph(offHeapVectors, fieldInfo.getVectorSimilarityFunction());
// 计算当前处理的字段的索引文件信息的总长度,该信息会写入元信息文件
long vectorIndexLength = vectorIndex.getFilePointer() - vectorIndexOffset;
。。。(忽略和索引文件落盘无关逻辑)
} finally {
。。。(忽略和索引文件落盘无关逻辑)
}
邻居信息写入向量索引文件的逻辑也比较直接,上代码:
private OnHeapHnswGraph writeGraph(
RandomAccessVectorValuesProducer vectorValues, VectorSimilarityFunction similarityFunction)
throws IOException {
// 构建HNSW(详细逻辑请看《lucene 9.1.0 HNSW的源码解析》)
HnswGraphBuilder hnswGraphBuilder =
new HnswGraphBuilder(
vectorValues, similarityFunction, maxConn, beamWidth, HnswGraphBuilder.randSeed);
hnswGraphBuilder.setInfoStream(segmentWriteState.infoStream);
OnHeapHnswGraph graph = hnswGraphBuilder.build(vectorValues.randomAccess());
// 邻居信息落盘
// HNSW总共有多少个节点,也就是一共有多少个向量。
int countOnLevel0 = graph.size();
// 从对底层开始处理每一层的邻居信息
for (int level = 0; level < graph.numLevels(); level++) {
// 获取当前层的节点迭代器
NodesIterator nodesOnLevel = graph.getNodesOnLevel(level);
while (nodesOnLevel.hasNext()) {
int node = nodesOnLevel.nextInt();
// 获取当前层当前节点的邻居信息
NeighborArray neighbors = graph.getNeighbors(level, node);
// 邻居的总数,因为不是每个节点都是maxConn个邻居
int size = neighbors.size();
// 先写入邻居的个数
vectorIndex.writeInt(size);
// 先对所有邻居按照节点编号从小到大排序,以后如果需要确认某个节点是否是其邻居,就可以通过二分查找了
int[] nnodes = neighbors.node();
Arrays.sort(nnodes, 0, size);
// 写入所有的邻居节点编号
for (int i = 0; i < size; i++) {
int nnode = nnodes[i];
vectorIndex.writeInt(nnode);
}
// 对于邻居没有达到maxConn个用0补齐,这是为了方便计算每个节点邻居存储的起始offset,后面读取的时候会介绍。
for (int i = size; i < maxConn; i++) {
vectorIndex.writeInt(0);
}
}
}
return graph;
}
vem文件生成
向量元信息文件存储的信息是为了读取向量数据文件,向量索引文件以及恢复HNSW结构时用的。
向量元信息包括了每个字段的在向量数据文件中的起始位置和数据长度,再向量索引数据文件中的起始位置和数据长度,每一层的节点数据,包含该字段的所有文档id,还有一些向量度量指标,向量维度,最大邻居个数maxConn,以及每一层的节点。这些信息的写入也比较简单:
private void writeMeta(
FieldInfo field, // 当前处理的向量字段信息
long vectorDataOffset, // 当前字段在向量数据文件中的起始位置
long vectorDataLength, // 当前字段的向量数据总长度
long vectorIndexOffset, // 当前字段在向量索引文件中的起始位置
long vectorIndexLength, // 当前字段在向量索引数据总长度
DocsWithFieldSet docsWithField, // 包含当前字段的的文档位图
OnHeapHnswGraph graph) // HNSW,用来获取每层的节点
throws IOException {
// 写入当前处理的字段的编号
meta.writeInt(field.number);
// 写入向量字段的距离度量方式
meta.writeInt(field.getVectorSimilarityFunction().ordinal());
// 写入当前字段在向量数据文件中的起始位置
meta.writeVLong(vectorDataOffset);
// 写入当前字段的向量数据总长度
meta.writeVLong(vectorDataLength);
// 写入当前字段在向量索引文件中的起始位置
meta.writeVLong(vectorIndexOffset);
// 写入当前字段在向量索引数据总长度
meta.writeVLong(vectorIndexLength);
// 写入当前字段的向量的维度
meta.writeInt(field.getVectorDimension());
int count = docsWithField.cardinality();
// 写入所有包含此字段的文档总数
meta.writeInt(count);
// 如果所有的文档都包含此字段,则写入-1作为标记
if (count == maxDoc) {
meta.writeByte((byte) -1);
} else {
// 否则写0,表示只有部分文档包含此字段
meta.writeByte((byte) 0);
DocIdSetIterator iter = docsWithField.iterator();
// 遍历所有的文档,写入文档编号
for (int doc = iter.nextDoc(); doc != DocIdSetIterator.NO_MORE_DOCS; doc = iter.nextDoc()) {
meta.writeInt(doc);
}
}
// 写入最大邻居个数
meta.writeInt(maxConn);
// 如果没有节点,则写入0作为标记
if (graph == null) {
meta.writeInt(0);
} else {
// 否则写入hnsw的总层数
meta.writeInt(graph.numLevels());
// 从低到高遍历所有的层
for (int level = 0; level < graph.numLevels(); level++) {
NodesIterator nodesOnLevel = graph.getNodesOnLevel(level);
// 写入当前层的节点个数
meta.writeInt(nodesOnLevel.size());
// 因为第0层默认包含所有的节点,因此从第一层开始写入所有的节点
if (level > 0) {
while (nodesOnLevel.hasNext()) {
int node = nodesOnLevel.nextInt();
meta.writeInt(node);
}
}
}
}
}
文件读取
vec和vex文件读取
HNSW的结构从文件恢复的逻辑都在Lucene91HnswVectorsReader中。我们先看下Lucene91HnswVectorsReader中的成员变量:
// 所有字段的信息
private final FieldInfos fieldInfos;
// key是向量字段名,向量字段元信息从元信息文件中解析存在在FieldEntry中
private final Map<String, FieldEntry> fields = new HashMap<>();
// 向量数据文件,可以根据FieldEntry中的信息获取到特定字段的所有向量数据
private final IndexInput vectorData;
// 向量索引文件(邻居信息),可以根据FieldEntry中的信息获取到特定字段的所有邻居数据
private final IndexInput vectorIndex;
在Lucene91HnswVectorsReader构造函数中会解析向量元信息文件,构建所有字段的FieldEntry,FieldEntry是用来从数据文件中构建HNSW的关键,具体后面会介绍。Lucene91HnswVectorsReader的构造函数中逻辑非常清楚,解析元信息文件,构建所有字段的FieldEntry对象,缓存起来,然后读取向量数据和向量索引数据,具体如下:
Lucene91HnswVectorsReader(SegmentReadState state) throws IOException {
this.fieldInfos = state.fieldInfos;
// 解析向量元信息文件,是最为核心的逻辑
int versionMeta = readMetadata(state);
boolean success = false;
try {
// 读取向量数据
vectorData =
openDataInput(
state,
versionMeta,
Lucene91HnswVectorsFormat.VECTOR_DATA_EXTENSION,
Lucene91HnswVectorsFormat.VECTOR_DATA_CODEC_NAME);
// 读取向量索引数据
vectorIndex =
openDataInput(
state,
versionMeta,
Lucene91HnswVectorsFormat.VECTOR_INDEX_EXTENSION,
Lucene91HnswVectorsFormat.VECTOR_INDEX_CODEC_NAME);
success = true;
} finally {
if (success == false) {
IOUtils.closeWhileHandlingException(this);
}
}
}
vem文件读取
元信息文件解析过程中会做一些校验,这部分不是重点,大家可以自行翻阅源码。vem文件的解析在readMetadata方法中,我们只关心readFields的逻辑,它是处理所有字段元信息的入口:
private int readMetadata(SegmentReadState state) throws IOException {
String metaFileName =
IndexFileNames.segmentFileName(
state.segmentInfo.name, state.segmentSuffix, Lucene91HnswVectorsFormat.META_EXTENSION);
int versionMeta = -1;
try (ChecksumIndexInput meta = state.directory.openChecksumInput(metaFileName, state.context)) {
Throwable priorE = null;
try {
versionMeta =
CodecUtil.checkIndexHeader(
meta,
Lucene91HnswVectorsFormat.META_CODEC_NAME,
Lucene91HnswVectorsFormat.VERSION_START,
Lucene91HnswVectorsFormat.VERSION_CURRENT,
state.segmentInfo.getId(),
state.segmentSuffix);
// 解析所有向量字段的元信息
readFields(meta, state.fieldInfos);
} catch (Throwable exception) {
priorE = exception;
} finally {
CodecUtil.checkFooter(meta, priorE);
}
}
return versionMeta;
}
在readFields中,首先读取的是字段编号,由字段编号可以获取字段信息做校验,我们把元信息文件的结构图拿过来对比看下,如下图所示存储在第一个的就是字段编号:

private void readFields(ChecksumIndexInput meta, FieldInfos infos) throws IOException {
// 遍历所有的字段元信息,指导发现了-1结束标记(还记得落盘中说向量元信息的结束标记吗)
for (int fieldNumber = meta.readInt(); fieldNumber != -1; fieldNumber = meta.readInt()) {
FieldInfo info = infos.fieldInfo(fieldNumber);
if (info == null) {
throw new CorruptIndexException("Invalid field number: " + fieldNumber, meta);
}
// 解析元信息数据,封装成FieldEntry对象
FieldEntry fieldEntry = readField(meta);
// 向量维度和向量数据长度的校验
validateFieldEntry(info, fieldEntry);
// 缓存字段的FieldEntry信息
fields.put(info.name, fieldEntry);
}
}
在readFields遍历所有的字段调用readField方法,它是构建FieldEntry的入口。readField中会先调用readSimilarityFunction是读取距离度量similarityFunction,它在元信息文件中的第二个,如下图箭头所示,有它可以知道向量的度量函数:

private FieldEntry readField(DataInput input) throws IOException {
// 读取距离度量信息
VectorSimilarityFunction similarityFunction = readSimilarityFunction(input);
// 构建字段的FieldEntry
return new FieldEntry(input, similarityFunction);
}
private VectorSimilarityFunction readSimilarityFunction(DataInput input) throws IOException {
int similarityFunctionId = input.readInt();
if (similarityFunctionId < 0
|| similarityFunctionId >= VectorSimilarityFunction.values().length) {
throw new CorruptIndexException(
"Invalid similarity function id: " + similarityFunctionId, input);
}
return VectorSimilarityFunction.values()[similarityFunctionId];
}
向量元信息文件剩余部分的解析都在FieldEntry的构造函数中,比较长,在正式解析之前,看下FieldEntry有哪些成员变量,这些成员变量也是解析元信息文件之后的用来存储元信息的:
// 这几个就不再说了
final VectorSimilarityFunction similarityFunction;
final long vectorDataOffset;
final long vectorDataLength;
final long vectorIndexOffset;
final long vectorIndexLength;
final int maxConn;
final int numLevels;
final int dimension;
private final int size;
// 存储的是节点id对应的docId
final int[] ordToDoc;
// 根据节点id获取docId操作器
private final IntUnaryOperator ordToDocOperator;
// 每一层中的所有节点,注意构建的时候已经决定了每层的节点编号是从小到大的
final int[][] nodesByLevel;
// 每一层中邻居信息在向量文件中索引文件的起始位置,这个是提前算出来的,怎么算后面有解释
final long[] graphOffsetsByLevel;
FieldEntry的构造函数中的逻辑我们分成四部分来看,第一部分解析下图所示的箭头区域,对照图看代码,非常简单:

FieldEntry(DataInput input, VectorSimilarityFunction similarityFunction) throws IOException {
this.similarityFunction = similarityFunction;
vectorDataOffset = input.readVLong();
vectorDataLength = input.readVLong();
vectorIndexOffset = input.readVLong();
vectorIndexLength = input.readVLong();
dimension = input.readInt();
size = input.readInt();
。。。(解析文档编号)
。。。(解析每一层的node)
。。。(初始化graphOffsetsByLevel)
}
第二部分是解析包含此字段的文档列表,如下图箭头所示的信息:
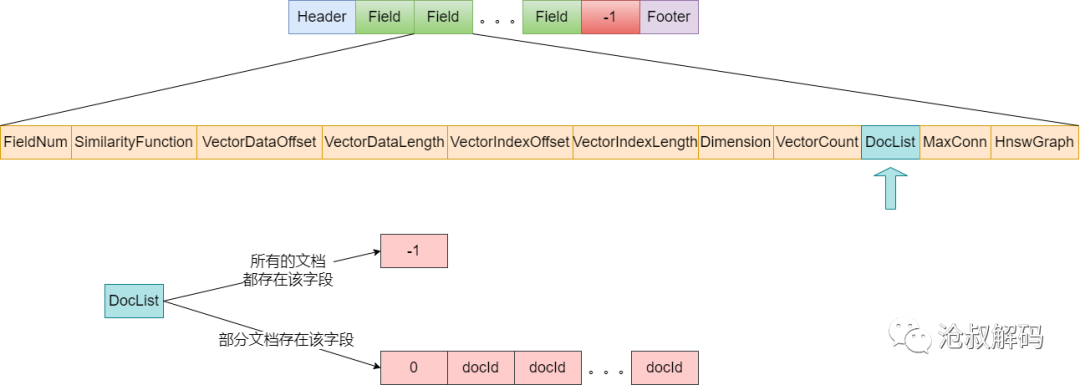
FieldEntry(DataInput input, VectorSimilarityFunction similarityFunction) throws IOException {
。。。(解析部分元信息)
// 读取是否是稀有数据的标记
int denseSparseMarker = input.readByte();
if (denseSparseMarker == -1) {
// -1代表所有的文档都包含该字段
ordToDoc = null;
} else {
// 一次解析所有的文档id,放入ordToDoc数组中,数组的小标是节点编号,数组值就是docid
ordToDoc = new int[size];
for (int i = 0; i < size; i++) {
int doc = input.readInt();
ordToDoc[i] = doc;
}
}
ordToDocOperator = ordToDoc == null ? IntUnaryOperator.identity() : (ord) -> ordToDoc[ord];
。。。(解析每一层的节点)
。。。(初始化graphOffsetsByLevel)
}
第三部分解析HNSW的元信息,包括最大邻居个数和所有层的节点信息,如下图箭头所示
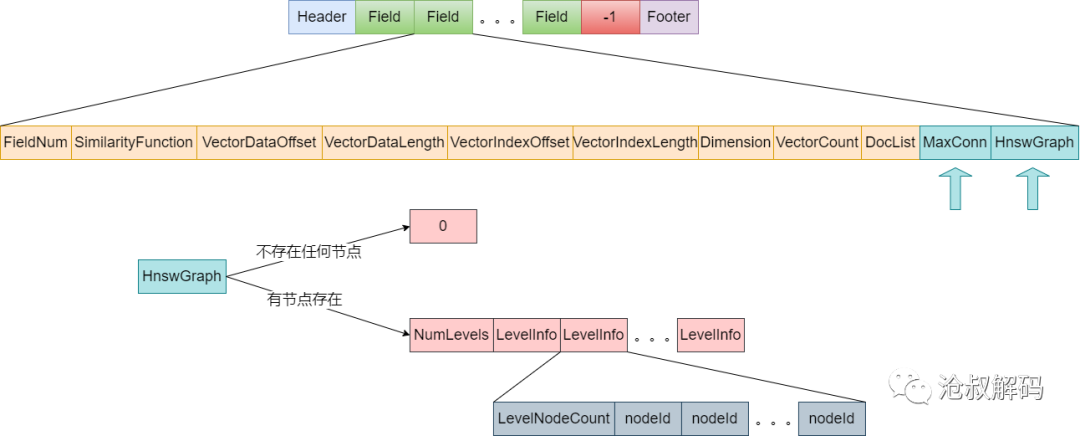
FieldEntry(DataInput input, VectorSimilarityFunction similarityFunction) throws IOException {
。。。(解析部分元信息)
。。。(解析文档编号)
// 最大邻居个数
maxConn = input.readInt();
// HNSW的层数
numLevels = input.readInt();
nodesByLevel = new int[numLevels][];
// 遍历所有层
for (int level = 0; level < numLevels; level++) {
// 当前层的节点个数
int numNodesOnLevel = input.readInt();
if (level == 0) {
// 第0层默认存储了所有的节点
nodesByLevel[0] = null;
} else {
nodesByLevel[level] = new int[numNodesOnLevel];
for (int i = 0; i < numNodesOnLevel; i++) {
// 获取节点编号
nodesByLevel[level][i] = input.readInt();
}
}
}
。。。(初始化graphOffsetsByLevel)
}
第四部分和前面都不同,前面都是通过解析文件直接获取的。第四部分是通过计算得到每层邻居数据的起始位置,提前保存起来,在向量近邻检索的时候可以直接用:
FieldEntry(DataInput input, VectorSimilarityFunction similarityFunction) throws IOException {
。。。(解析部分元信息)
。。。(解析文档编号)
。。。(解析每一层的节点)
// 每一层的邻居数据的起始位置
graphOffsetsByLevel = new long[numLevels];
for (int level = 0; level < numLevels; level++) {
if (level == 0) {
graphOffsetsByLevel[level] = 0;
} else {
int numNodesOnPrevLevel = level == 1 ? size : nodesByLevel[level - 1].length;
// 1 + maxConn:1个int记录真实的邻居个数 + maxConn个int记录所有的邻居编号
// (1 + maxConn) * Integer.BYTES * numNodesOnPrevLevel:前一层的邻居数据长度
// graphOffsetsByLevel[level - 1]:前一层邻居数据的起始位置
// 从而得到graphOffsetsByLevel[level]是当前层邻居数据的起始位置
graphOffsetsByLevel[level] =
graphOffsetsByLevel[level - 1] + (1 + maxConn) * Integer.BYTES * numNodesOnPrevLevel;
}
}
}
有了以上信息,就可以恢复字段的HNSW图结构:
public HnswGraph getGraph(String field) throws IOException {
FieldInfo info = fieldInfos.fieldInfo(field);
if (info == null) {
throw new IllegalArgumentException("No such field '" + field + "'");
}
FieldEntry entry = fields.get(field);
if (entry != null && entry.vectorIndexLength > 0) {
// 通过FieldEntry构建HNSW
return getGraph(entry);
} else {
return HnswGraph.EMPTY;
}
}
private HnswGraph getGraph(FieldEntry entry) throws IOException {
// 向量索引数据(邻居信息数据)
IndexInput bytesSlice =
vectorIndex.slice("graph-data", entry.vectorIndexOffset, entry.vectorIndexLength);
// 构建HNSW
return new OffHeapHnswGraph(entry, bytesSlice);
}
在HNSW构建的源码解析中我们说到,构建的时候使用OnHeapHnswGraph表示图结构,加载文件恢复HNSW图结构使用的是OffHeapHnswGraph。OnHeapHnswGraph已经介绍过了,现在我们来看下OffHeapHnswGraph。首先看下OffHeapHnswGraph的成员变量:
// 向量索引文件数据
final IndexInput dataIn;
// 每层的所有节点
final int[][] nodesByLevel;
// 在向量索引文件中的每层的邻居信息起始位置
final long[] graphOffsetsByLevel;
// HNSW的层数
final int numLevels;
// 搜索的起始节点
final int entryNode;
// hnsw中的向量总数
final int size;
// 每个节点的邻居信息在向量索引文件中占用的字节,
// 因为所有节点邻居都是maxConn个(不足的文件写入会补0),所以长度是固定的,可以提前算出来
final long bytesForConns;
// 邻居的个数
int arcCount;
// 下一个要遍历的邻居编号
int arcUpTo;
// 邻居编号
int arc;
上面的成员变量中重点看entryNode和bytesForConns的初始化,其他都比较简单:
OffHeapHnswGraph(FieldEntry entry, IndexInput dataIn) {
// 只要有数据,就把搜索的起始遍历节点设置为最顶层的第一个节点
this.entryNode = numLevels > 1 ? nodesByLevel[numLevels - 1][0] : 0;
// 加1是因为存储所有邻居信息之前会额外存储真实邻居个数(并不是所有的节点邻居都是maxConn,有些是补0的)
this.bytesForConns = ((long) entry.maxConn + 1) * Integer.BYTES;
}
OffHeapHnswGraph中方法重点看下怎么定位和遍历指点节点的邻居,在《lucene 9.1.0 HNSW的源码解析》我们已经说过了,邻居查找是通过seek定位到起始位置,然后再使用nextNeighbor进行遍历:
// 定位邻居信息的起始位置思路:
// nodesByLevel[level]存放的是第level层中所有的节点,节点是按编号从到到大排列。
// 对于第0层,所有节点都存在,所以节点编号和数组下标一一对应。
// 对于其他层,可以通过二分法找到对应节点在数组中的下标,数组的下标i就可以用来确定第i个节点邻居信息的起始位置
public void seek(int level, int targetOrd) throws IOException {
// 先找到节点编号为targetOrd在数组中的下标
int targetIndex =
level == 0
// 第0层包含所有的节点,数组下标就是节点的编号,可以直接获取
? targetOrd
// 二分法查找指定值的数组下标
: Arrays.binarySearch(nodesByLevel[level], 0, nodesByLevel[level].length, targetOrd);
// graphOffsetsByLevel[level]是第level层的所有节点的邻居信息的起始位置。
// bytesForConns是一个节点的邻居信息占用的大小
// graphOffsetsByLevel[level] + targetIndex * bytesForConns就是第targetIndex节点邻居信息的起始位置
long graphDataOffset = graphOffsetsByLevel[level] + targetIndex * bytesForConns;
// 定位到节点邻居信息的起始位置
dataIn.seek(graphDataOffset);
// 获取真实邻居总数
arcCount = dataIn.readInt();
// 当前邻居编号初始化为-1,表示还没开始遍历
arc = -1;
// 下一个要遍历的编号
arcUpTo = 0;
}
@Override
public int nextNeighbor() throws IOException {
// 判断是否遍历结束,注意编号是从0开始的
if (arcUpTo >= arcCount) {
return NO_MORE_DOCS;
}
++arcUpTo;
// 读取邻居编号
arc = dataIn.readInt();
return arc;
}
至此,支撑HNSW检索的信息都已经可以直接获取到了,至于HNSW如何用这些信息进行检索,请参考前文《lucene 9.1.0 HNSW的源码解析》。
文件读取总结
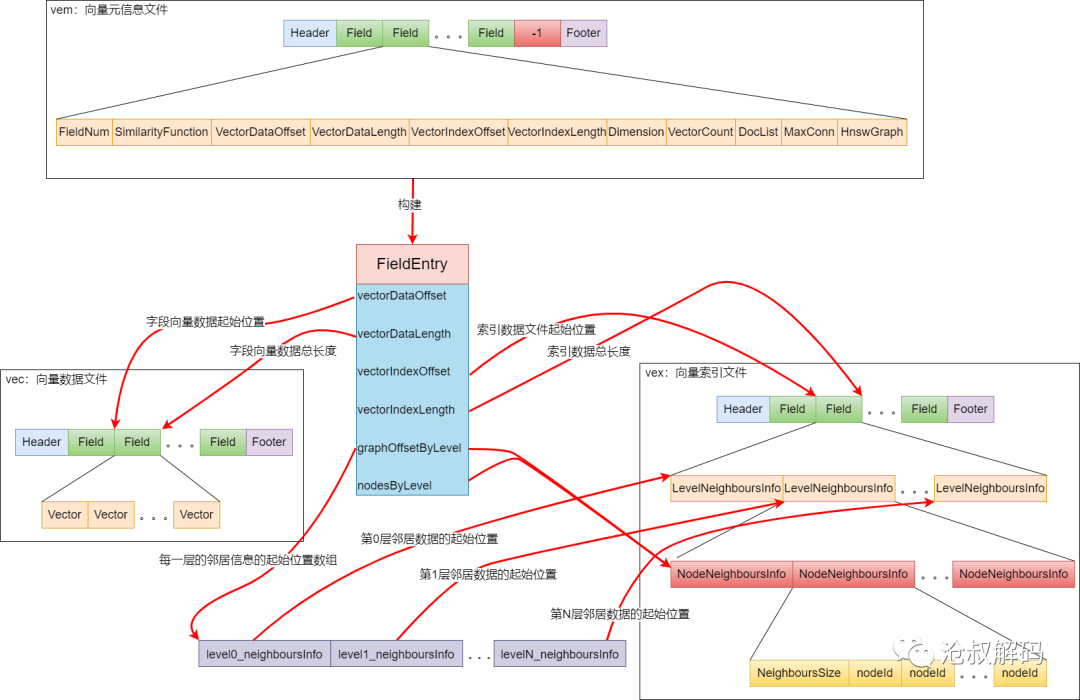
上图是lucene向量数据文件解析的全局示意,对照这个图,我们梳理下文件解析的整体思路:
1.读取向量元信息文件,解析元信息构建FieldEntry对象。2.通过FieldEntry中的vectorDataOffset和vectorDataLength可以读取指定字段的向量数据。3.通过FieldEntry中的vectorIndexOffset和vectorIndexLength可以读取指定字段的向量索引数据。4.通过FieldEntry中的graphOffsetByLevel和nodesByLevel可以读取指定字段的某一层的所有邻居信息。5.通过FieldEntry构建OffHeapHnswGraph就可支撑向量近邻检索。